알고리즘

시간 복잡도 (Time Complexity)와 공간 복잡도 (Space Complexity)
알고리즘 성능 평가 평가하기 위해 '복잡도(Complexity)'의 척도를 사용한다. 그중 시간 복잡도와 공간 복잡도의 개념이 나오며, 동일한 기능을 수행하는 알고리즘이 있을 때 복잡도가 낮을 수록 좋은 알고리즘이라 말한다고 한다. 시간 복잡도: 특정한 크기의 입력에 대하여 알고리즘의 수행 시간 분석 공간 복잡도: 특정한 크기의 입력에 대하여 알고리즘의 메모리 사용량 분석 1. 시간 복잡도 시간 복잡도는 특정 알고리즘이 어떤 문제를 해결하는데 걸리는 시간을 의미한다. 같은 결과를 갖는 프로그래밍 소스도 작성 방법에 따라 걸리는 시간이 달라지며, 같은 결과를 같는 소스라면 시간이 적게 걸리는 것이 좋은 소스다. 빅-오 표기법 예를 들어, 동전을 튕겨 뒷면이 나올 확률을 이야기 할 때 운이 좋으면 1번에 뒷..
[실1] 11403 - 경로 찾기
플로이드 와샬 #include #define INF 100000 #define NODE 1000 using namespace std; int graph[NODE][NODE]{ 0 }; void Floyd_washall() { int n; cin >> n; for (int i = 0; i > graph[i][j]; } for (int k = 0; k < n; k++) // 거쳐가는 노드 { for (int i = 0; i < n; i++) // 출발지 노드 { for (int j = 0; j < n; j++) // 도착지 노드 { if (graph[i][k] && graph[k][j]) graph[i][j]= 1; } } } ..

C++ STL 설명과 for-range 기반 loop
STL(Standard Template Library)은 C++ 내 템플릿 클래스들의 집합이며, 개발자에게 도움줄 수많은 자료구조와 함수들이 구현 되어있다. 기본 4가지로 구성 되어있다. 알고리즘 헤더 파일 내 (정렬, 탐색 컨테이너 (선형,비선형 자료구조) 예) , 함수 이터레이터 (반복자) 모든 컨테이너들은 이를 지원하지 않음. STL은 기본적으로 범위 기반 for문을 돌려 원소에 접근할 수가 있다. 핵심은 4번에 있다, 이를 실행할 수 있는 조건이 바로 .begin() 함수다 즉 첫 원소의 주소를 이터레이터 형태로 반환하는 함수다. 예) for(auto item : 컨테이너 이름) 여기서 한 가지 의문점이 들 수도 있는데 const auto : const auto& : auto : auto& : 위..

BOIDS (군중 알고리즘) RTS AI
스타크래프트의 하이브리드 최적 경로 마이크로 관리는 RTS 게임의 가장 중요한 기능이다. 싱글 유닛 또는 한 그룹의 유닛을 드래그해서 선택을 하여 적을 공격하게끔 하는 것이며 이러한 AI 기능은 구현하고자 할 때 큰 골치거리다. 두 가지의 구현 방법이 있다. 퍼텐셜 필드 알고리즘 : 목표점으로 이끄는(attractive) 인공적인 포텐셜 필드와 장애물로부터 멀어지게 내보내는(repulsive) 인공적인 포텐셜 필드를 형상공간에 구축하는 알고리즘. 군중 이동 알고리즘 : 군중 이동(새 떼라던지 물고기들의 움직임 등 여러 집단이 함께 움직이는)에 대한 알고리즘. 게임 유닛들의 내비게이션은 주로 A*와 같은 최단 경로 알고리즘을 사용한다. 하지만, RTS와 같이 월드가 수시로 변화하는 게임에는 적합하지가 않다..
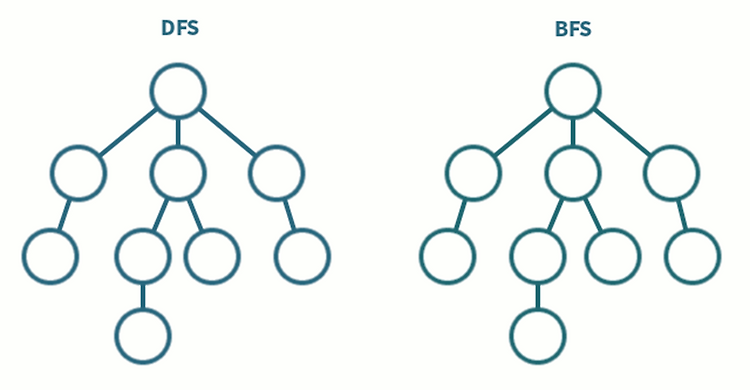
깊이 우선 탐색 BFS / 너비 우선 탐색 BFS 개념
깊이 우선 탐색 (DFS; Depth First Search) 루트 노드에서 시작해서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 알고리즘을 의미한다. 미로를 탐색할 때 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 다시 가장 가까운 갈림길로 돌아와서 이곳으로부터 다른 방향으로 다시 탐색을 진행한다. 즉, 넓게(wide) 탐색하기 전에 깊게(deep) 탐색 하는 것이다. 빠르게 모든 경우의 수를 탐색하고자 할 때 사용한다. 스택 이나 재귀함수 로 구현한다. 너비 우선 탐색 (BFS; Breadth First Search) 루트 노드에서 시작해서 인접한 노드를 먼저 탐색 하는 알고리즘이다. 즉, 깊게 (deep) 탐색하기 전에 넓게 (wide) 탐색 하는 것이다. 두 ..
해시 테이블
해시 테이블은 (Key, Value)식으로 데이터를 저장하는 자료구조 중 하나로 key를 통해 평균 O(1)에 value를 검색할 수 있는 자료구조이다. 해시 테이블은 Key 값을 해시함수(Hash Function)를 사용하여 변환한 값을 색인(index)으로 삼는다. 해시 함수(Hash Function)을 사용해 Key 값을 색인(index)으로 변환하는 과정을 해싱(Hashing)이라고 한다. 해시 함수(Hash Function) 해시 함수의 가장 중요한 점은 고유한 인덱스를 만드는 것이다. 만약 중복되는 인덱스가 발생한다면 이는 충돌(Collision)으로 이어지게 된다. 따라서 해시 함수를 구현하는 해시 알고리즘을 적절히 구현하는 것이 중요하다. 해시 테이블에 사용되는 대표적인 해시 알고리즘에는 ..
레드-블랙 트리(Red-Black Tree)
레드-블랙 트리(Red-Black Tree) 레드-블랙 트리는 자가 균형 이진 탐색 트리이다. 레드-블랙 트리는 다음과 같은 조건들을 만족한다. 1. 모든 노드는 빨간색 혹은 검은색이다. 2. 루트 노드는 검은색이다. 3. 모든 리프 노드(NIL)들은 검은색이다. (NIL : null leaf, 자료를 갖지 않고 트리의 끝을 나타내는 노드) 4. 빨간색 노드의 자식은 검은색이다. == No Double Red(빨간색 노드가 연속으로 나올 수 없다) 5. 모든 리프 노드에서 Black Depth는 같다. == 리프노드에서 루트 노드까지 가는 경로에서 만나는 검은색 노드의 개수가 같다. 레드-블랙 트리 삽입 과정 위 설명만 보고는 레드-블랙 트리가 무엇인지 감이 쉽게 오지 않을 것이다. 레드-블랙 트리를 쉽..

[C] 이진 탐색 트리
이진탐색트리(Binary Search Tree)이란? 이진탐색트리란 다음과 같은 특징을 갖는 이진트리를 말한다. ( #이진트리 - 각 노드의 자식 노드가 최대 2개인 트리) 1. 각 노드에 중복되지 않는 키(key)가 있다. 2. 루트노드의 왼쪽 서브 트리는 해당 노드의 키보다 작은 키를 갖는 노드들로 이루어져 있다. 3. 루트노드의 오른쪽 서브 트리는 해당 노드의 키보다 큰 키를 갖는 노드들로 이루어져 있다. 4. 좌우 서브 트리도 모두 이진 탐색 트리여야 한다. 이진 탐색 트리의 특징 이진 탐색 트리는 기존 이진트리보다 탐색이 빠르다. 이진 탐색 트리의 탐색 연산은 트리의 높이(height)가 h라면 O(h)의 시간 복잡도를 갖는다. 이진 탐색 트리 탐색(Search) 이진 탐색 트리의 탐색은 다음과..

트리
트리(Tree)의 개념 트리는 노드로 이루어진 자료구조로 스택이나 큐와 같은 선형 구조가 아닌 비선형 자료구조이다. 트리는 계층적 관계를 표현하는 자료구조이다. 트리는 다음과 같은 특징들을 갖는다. 1. 트리는 하나의 루트 노드를 갖는다. 2. 루트 노드는 0개 이상의 자식 노드를 갖는다. 3. 자식 노드 또한 0개 이상의 자식 노드를 갖는다. 4. 노드(Node)들과 노드들을 연결하는 간선(Edge)들로 구성되어 있다. 트리에는 사이클(cycle)이 존재할 수 없다. 여기서 사이클이란 시작 노드에서 출발해 다른 노드를 거쳐 다시 시작 노드로 돌아올 수 있다면 사이클이 존재한다고 한다. 트리는 사이클(cycle)이 없는 하나의 연결 그래프(Connected Graph)라고 할 수 있다. 트리의 노드는 s..
트리 구현
#include #include #include // 트리 구조체 typedef struct treeNode { int data; treeNode* left; // 왼쪽 노드에 대한 포인터 treeNode* right; // 오른쪽 노드에 대한 포인터 }; // 트리 객체 초기화 treeNode* makeRootNode(int data, treeNode* leftNode, treeNode* rightNode) { treeNode* root = (treeNode*)malloc(sizeof(treeNode)); root->data = data; // data 초기화 root->left = leftNode; // 왼쪽 링크 초기화 root->right = rightNode; // 오른쪽 링크 초기화 retur..