
현재 프로젝트에서 사용 중인 스레드의 개수는 4개이다.
싱글 스레드 렌더링과 멀티스레드 렌더링의 성능을 비교해보겠다.
우선 사용하고 있는 메쉬 모델 데이터의 정보이다.

애니메이션 정보가 없는 스태틱 메쉬의 경우
vertex 정점 11,400개 / index 3,800개이다.
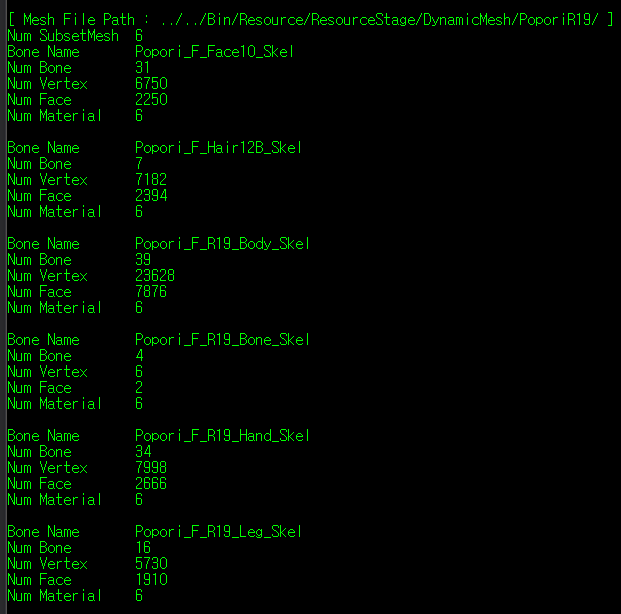
애니메이션 스키닝을 해야 하는 다이나믹 메쉬의 경우
vertex 정점 51,294개 / index 17,096개이다.
모든 오브젝트에 대해서 인스턴싱은 적용 X.
모든 오브젝트는 vertex 셰이더와 pixel 셰이더를 통해 렌더링 한다.
1. StaticMesh x1000
한 번 장면을 그릴 때마다 그리는 vertex의 개수는 11,400 * 1,000 = 11,400,000개.
그림자 깊이까지 총 2번을 그리므로 11,400,000 * 2 = 22,800,000개 이다.
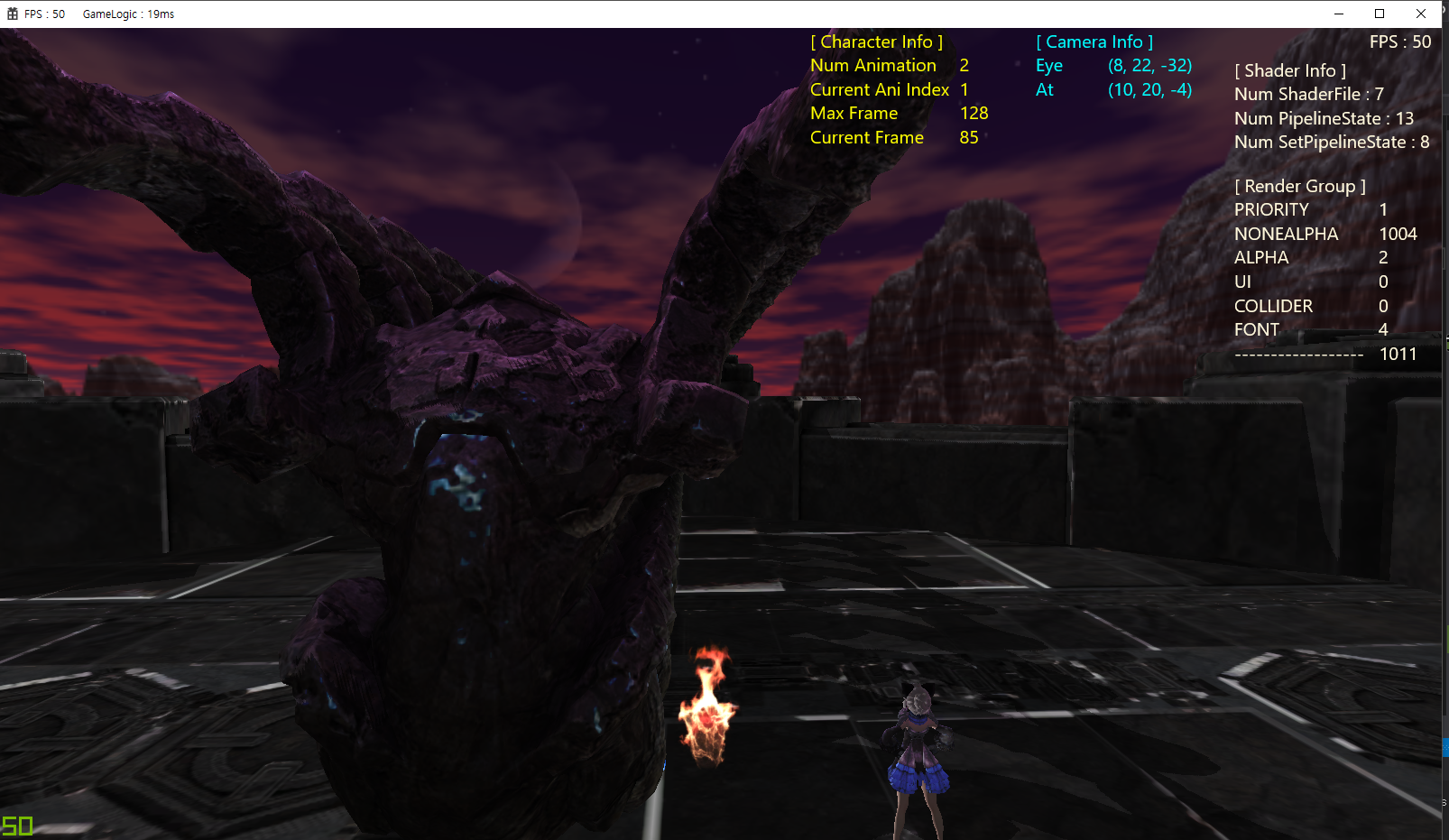
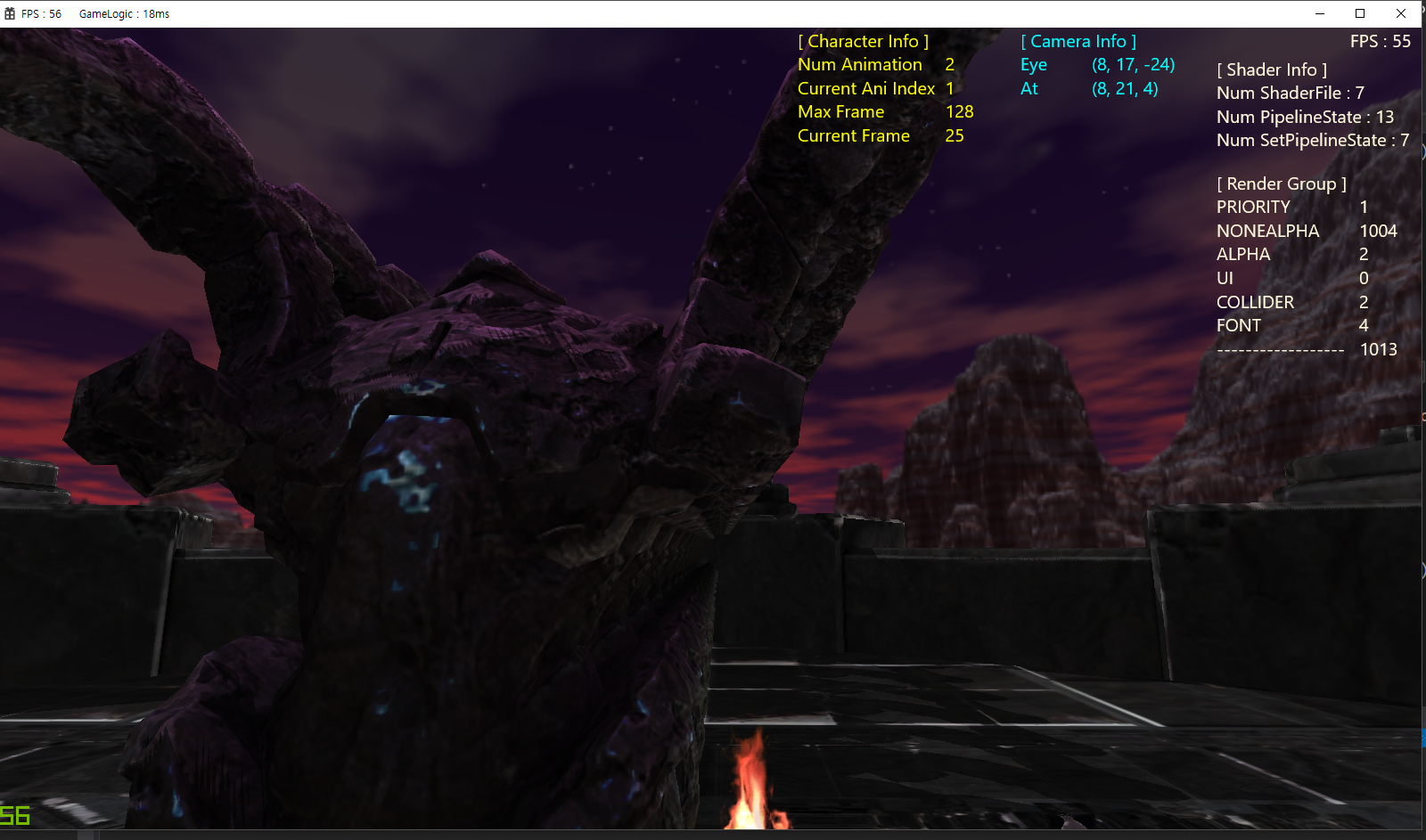
스태틱 메시 1,000개를 멀티 스레드 렌더링할 경우 약 55 FPS가 나온다.
(좌측 하단 or 우측 상단의 FPS 정보 출력)
성능이 약 10% 향상된 것을 확인할 수 있다. (50 FPS --> 55 FPS)
2. StaticMesh x3000
한 번 장면을 그릴 때마다 그리는 vertex의 개수는 11,400 * 3,000 = 34,200,000개.
그림자 깊이까지 총 2번을 그리므로 34,200,000 * 2 = 68,400,000개이다.
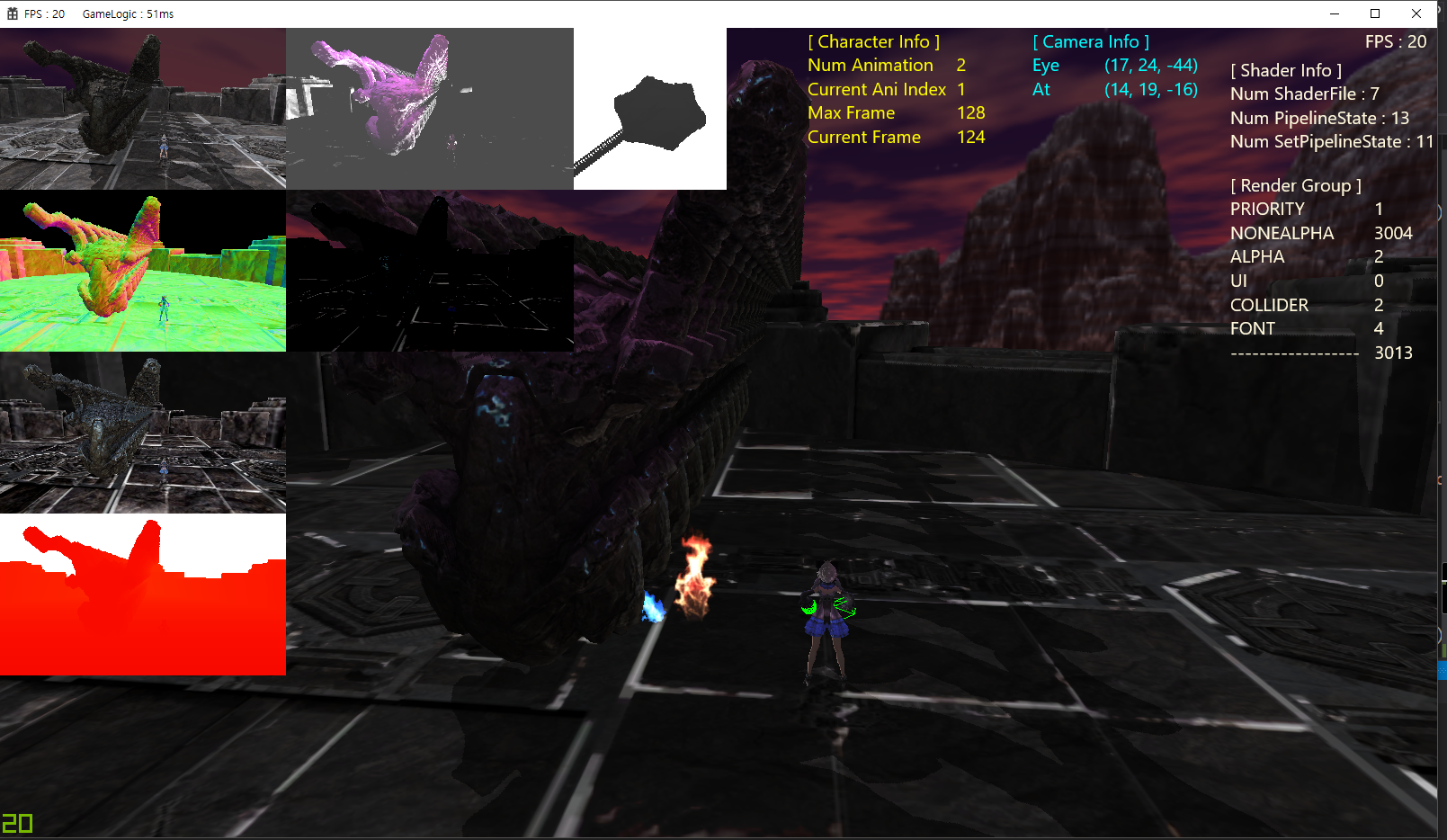
스태틱 메시 3,000개를 싱글 스레드 렌더링 할 경우 약 20 FPS가 나온다.
(좌측 하단 or 우측 상단의 FPS 정보 출력)
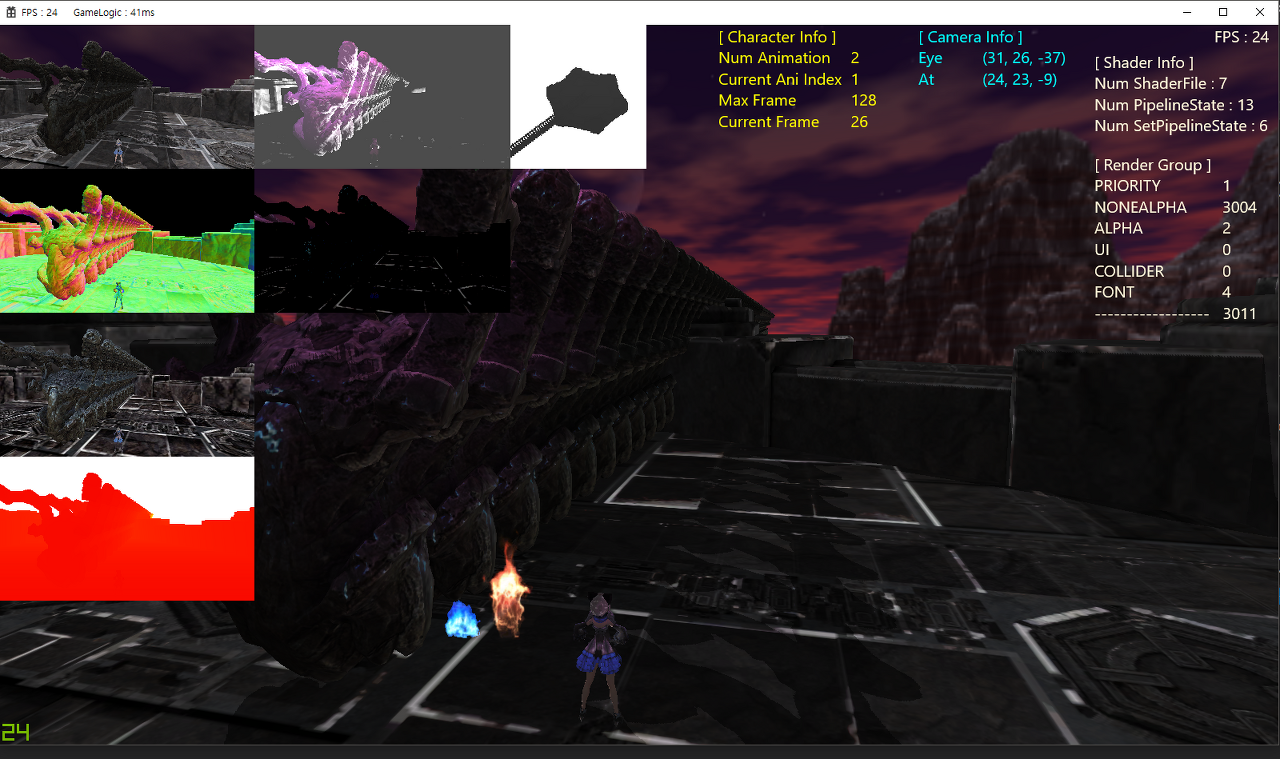
스태틱 메시 3,000개를 멀티 스레드 렌더링할 경우 약 24 FPS가 나온다.
(좌측 하단 or 우측 상단의 FPS 정보 출력)
성능이 약 20% 향상된 것을 확인할 수 있다. (20 FPS --> 24 FPS)
1. DynamicMesh x100
한 번 장면을 그릴 때마다 그리는 vertex의 개수는 51,294 * 100 = 5,129,400개.
그림자 깊이까지 총 2번을 그리므로 5,129,400 * 2 = 10,258,800개이다.
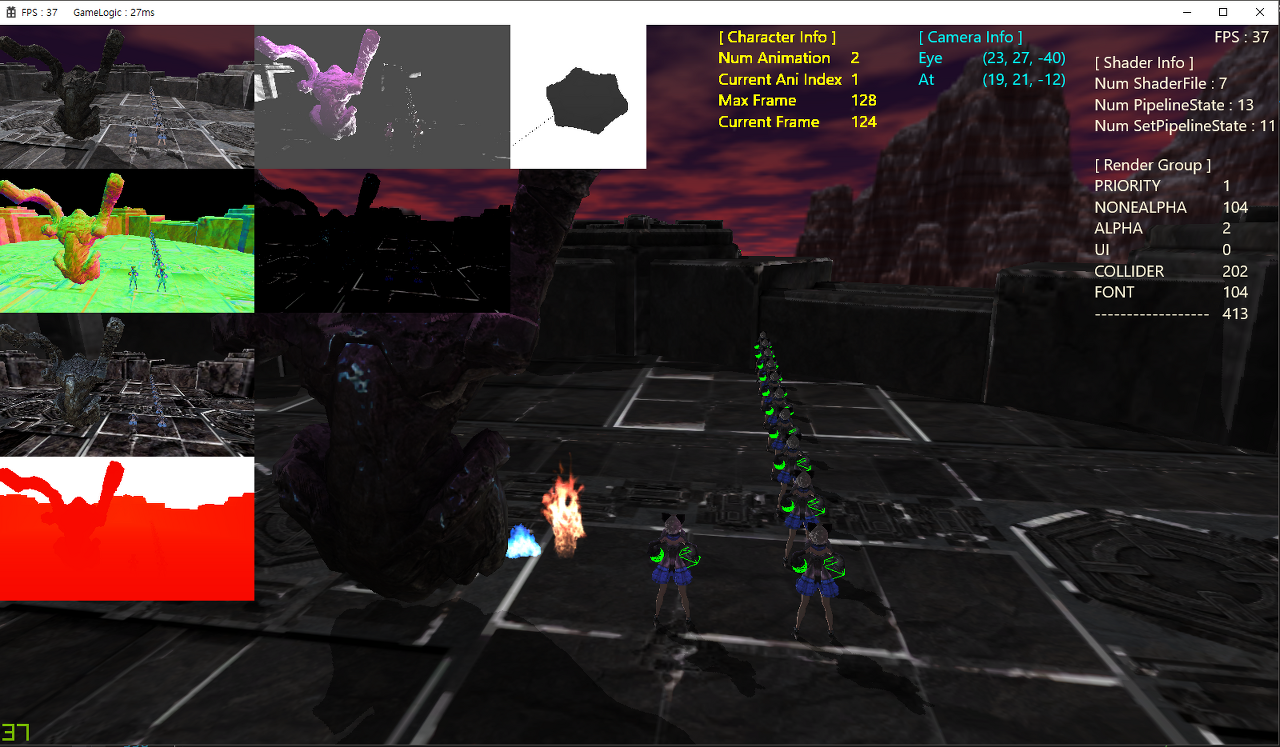
다이나믹 메시 100개를 싱글 스레드 렌더링 할 경우 약 36 ~ 37 FPS가 나온다.
(좌측 하단 or 우측 상단의 FPS 정보 출력)
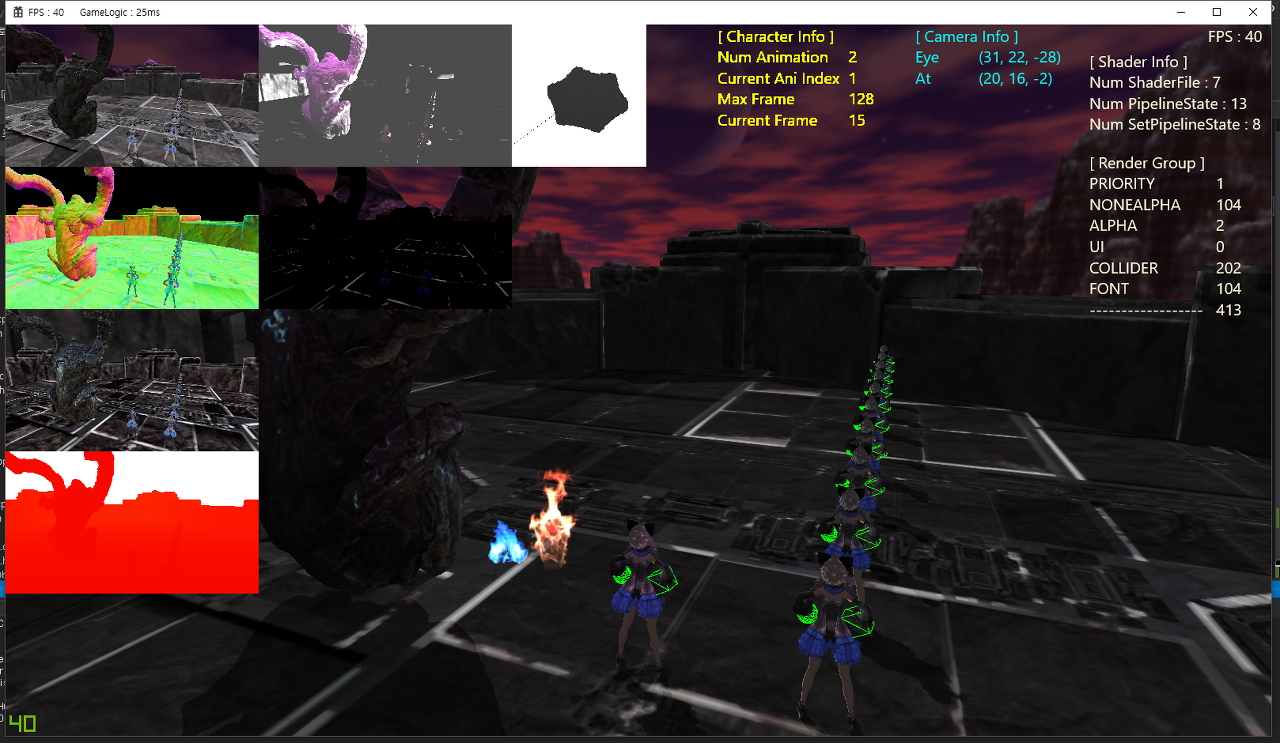
다이나믹 메시 100개를 멀티 스레드 렌더링할 경우 약 40 ~ 41 FPS가 나온다.
(좌측 하단 or 우측 상단의 FPS 정보 출력)
성능이 약 10% 향상된 것을 확인할 수 있다. (36 FPS --> 40 FPS)
2. DynamicMesh x200
한 번 장면을 그릴 때마다 그리는 vertex의 개수는 51,294 * 200 = 10,258,800개.
그림자 깊이까지 총 2번을 그리므로 10,258,800 * 2 = 20,517,600개이다.
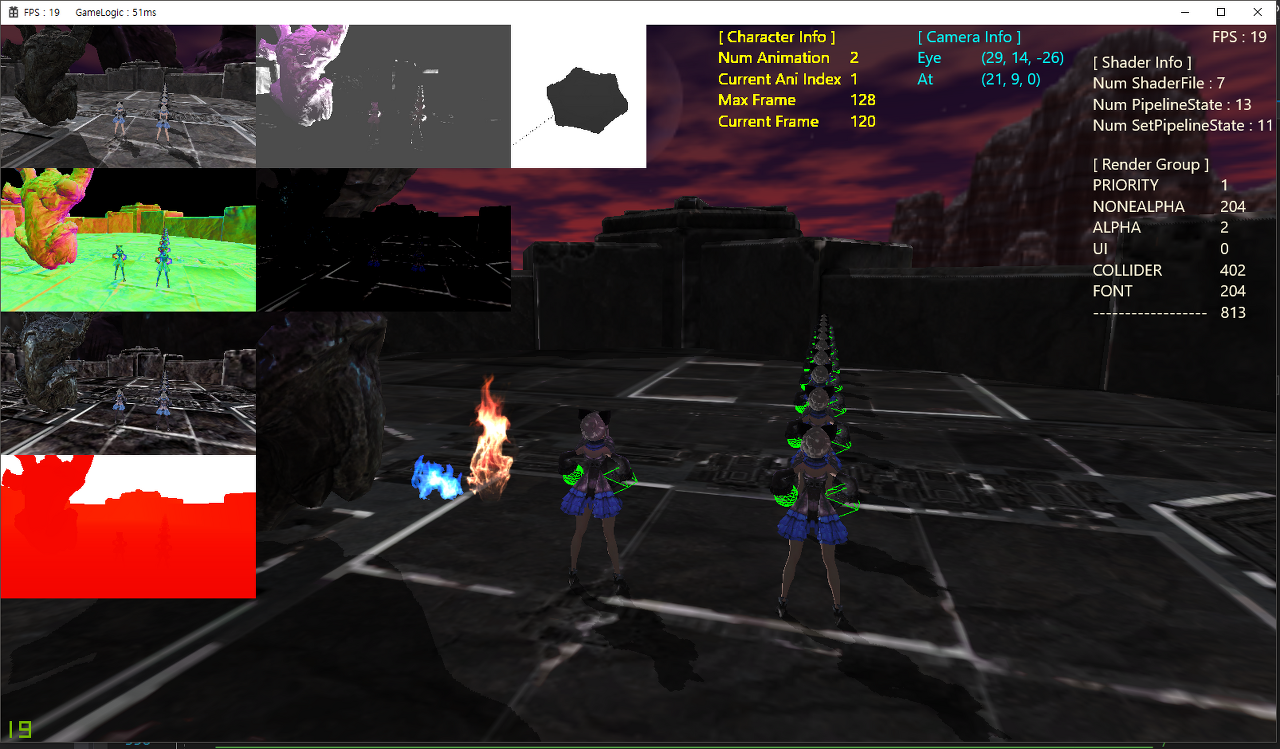
다이나믹 메시 200개를 싱글 스레드 렌더링 할 경우 약 19 ~ 20 FPS가 나온다.
(좌측 하단 or 우측 상단의 FPS 정보 출력)
다이나믹 메시 200개를 멀티 스레드 렌더링할 경우 약 22 ~ 23 FPS가 나온다.
(좌측 하단 or 우측 상단의 FPS 정보 출력)
성능이 약 10% ~ 15% 향상된 것을 확인할 수 있다. (20 FPS --> 23 FPS)
[ 정리 ]
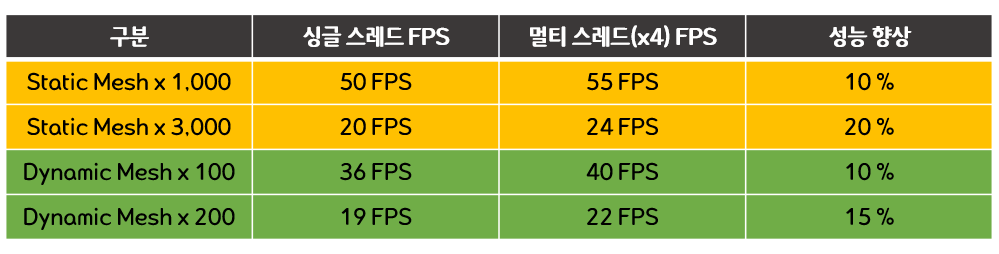
멀티스레드 렌더링을 할 경우 약 10% ~ 20%의 렌더링 성능 향상을 기대할 수 있다.
스레드를 4개를 사용하였지만 성능 향상이 4배가 되지 않는 이유는 다음과 같다.
1. DirectX 12에서 CommandList에 렌더링 명령을 동시에 4개의 스레드에서 담는 것이지
동시에 실행하는 것이 아니기 때문이다.
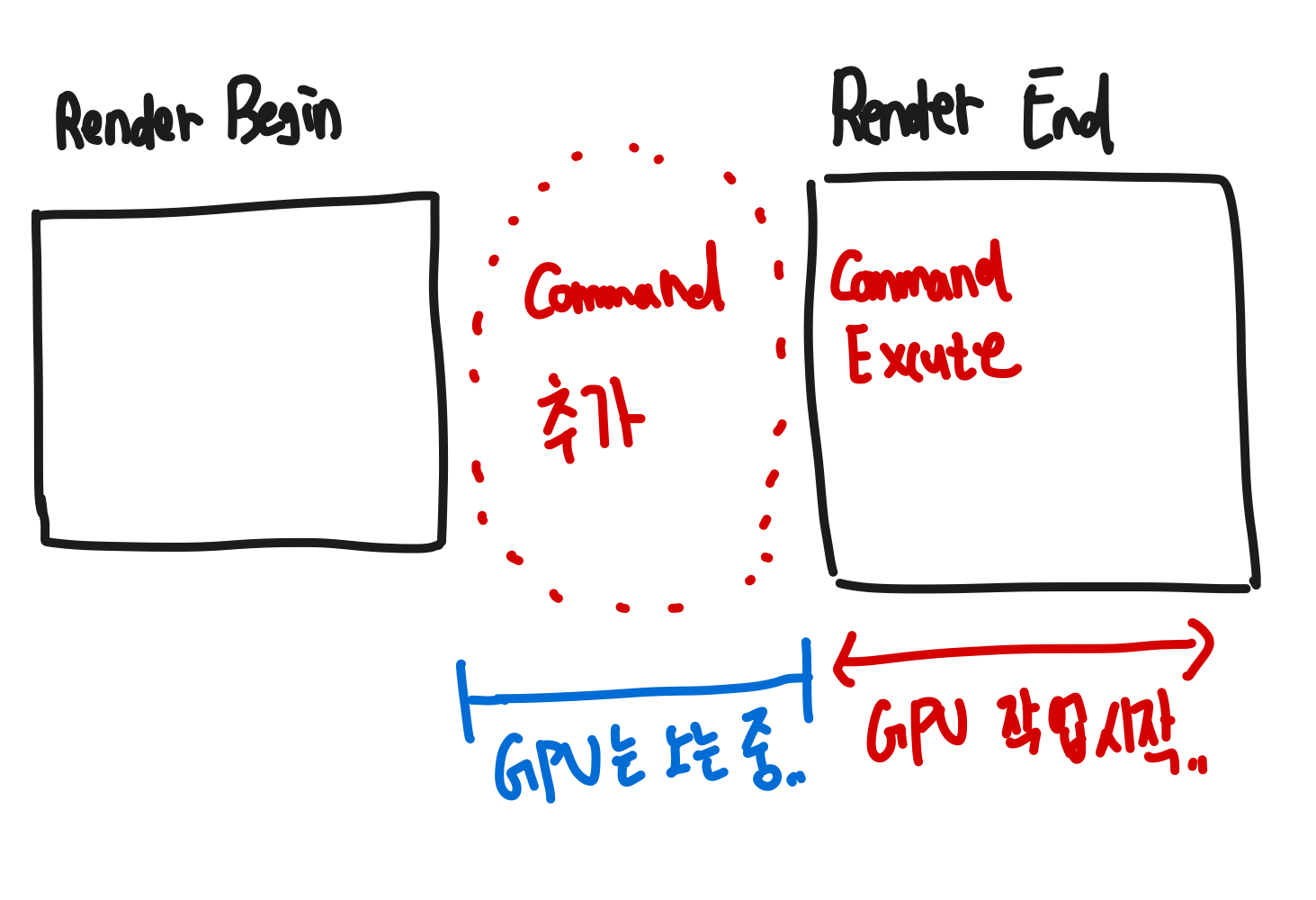
즉, 싱글 스레드 렌더링에서는 렌더링 명령들이 모두 들어온 이후에 GPU가 작업을 시작한다.
명령이 추가되는 동안에는 GPU는 일을 안 하고 놀고 있는 것이다.
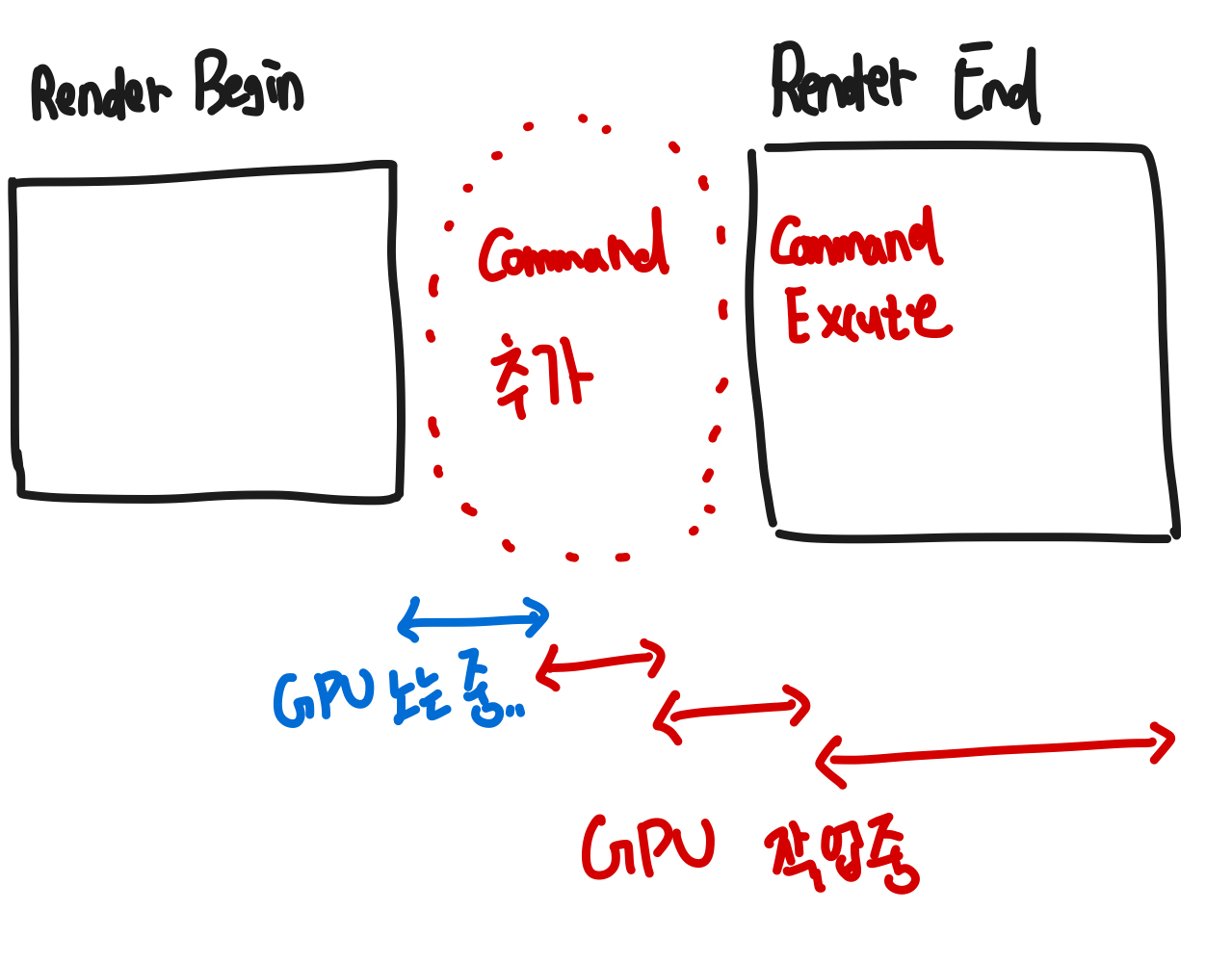
DirectX 12 멀티스레드 렌더링은
스레드(Thread)를 통해 명령들을 빠르게 GPU에 넣어줘서 실행시키고,
명령들이 실행되는 동시에 아직 남아있는 명령들을 GPU로 다시 보냄으로써
GPU가 렌더링 시작 시 쉬고 있는 시간을 최소화하는 것이 목적이다.
2. 렌더링 순서 동기화를 위한 ExecuteCommandLists() 함수 호출 횟수.
그림자 깊이 맵이 먼저 그려지고, 이후에 오브젝트들이 그려져야 하므로
이 동기화 순서를 맞추기 위해 ExecuteCommandLists() 함수 호출 횟수가 많아졌다.
ExecuteCommandLists()는 굉장히 무거운 작업을 하는 함수이기 때문에
호출 횟수가 많아지면 성능이 떨어지게 된다.
'그래픽스 > DirectX' 카테고리의 다른 글
| [Direct X] Constant Buffer(상수 버퍼) 란? (0) | 2023.07.14 |
|---|---|
| [DX11] 튜토리얼 4 - 3D 공간 (0) | 2023.07.14 |
| DirectX와 HLSL간의 행렬 순서와 연산 (0) | 2023.07.14 |
| [DX11] 튜토리얼 2 - 삼각형 렌더링 (0) | 2023.07.12 |
| DirectX 렌더 대상 뷰 (RTV) 생성 (0) | 2023.07.12 |