
정의
기존의 #include 방식인 Translation Unit 방식과는 다른, 별개와 컴파일되는 소스 코드 파일의 집합이다. Header파일을 사용하면서 생겨나는 많은 문제를 제거하거나 줄이고, 컴파일 시간을 단축하기도 한다.
선언된 모든 매크로, 전처리 지시문과 export 하지 않는 이름(names)들은 표시되지 않으며, 컴파일 할 때 영향을 주지 않는다. 또한 순서에 관계 없이 가져올 수 있다. (include, import) Module을 한 번 컴파일한 후에는 export된 모든 형식(Type), 함수 및 템플릿을 이진파일에 저장한다. 이 파일은 이전의 헤더 파일들보다 훨씬 빠르게 처리될 수 있다.
기존의 C++ 빌드 과정
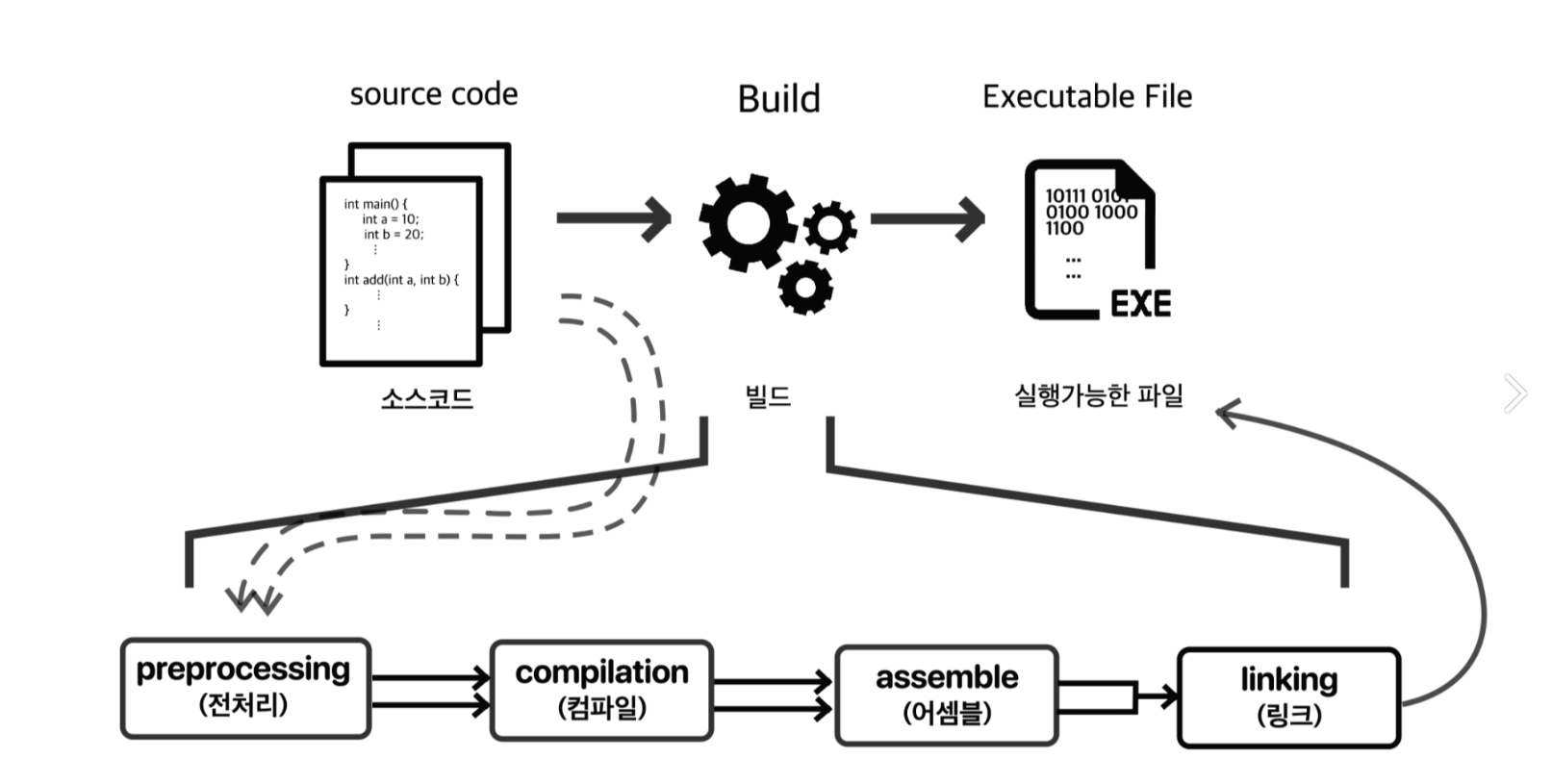
C++ 프로그램의 빌드 과정은 전처리, 컴파일, 링크로 구성된다.
전처리(Preprocessor)
전처리기는 소스 파일에 있는 #include나 #define 같은 지시문들을 처리한다.
#include 지시문을 헤더 파일로 치환하고 #define 지시문도 정의된 매크로로 치환한다.
#if, #else, #elif, #ifdef, #ifndef , #endif 같은 지시문을 기반으로 조건부 처리로 포함하거나 제외한다.
전처리기에서 생성된 구문을 번역 단위(translation unit) 라고 불리우고 이것을 컴파일러에 전달 한다.
컴파일(compilation)
컴파일 과정에서는 전달 받은 번역 단위에 담긴 c++ 소스 코드를 해석해서 어셈블리 코드로 변환한다.
어셈블리 코드에 대응 되는 이진 파일을 출력하는데 이것을 목적(object) 파일이라고 한다.
목적 파일들은 목적 파일이 정의하지 않은 Symbol들도 참조 할 수 있다.
링크(linking)
목적(Object) 파일들을 링크해서 하나의 실행 파일이나 공유, 정적 라이브러리 파일을 만든다. 여기서 목적 파일들의 Symbol을 검사해서 정상적인 참조인지 확인한다.
빌드 과정의 문제점
치환 문제
// main.cpp
int main()
{
return 0;
}
// main1.cpp
#include <iostream>
int main()
{
return 0;
}cl이나 g++ 명령어에 옵션을 통해서 빌드과정에서 생성되는 번역단위를 확인 할 수 있다.
# msvc의 경우
cl.exe /std:c++20 /c main.cpp /E > trans.log
cl.exe /std:c++20 /c main1.cpp /E > trans1.log
# gcc의 경우
g++ -E main.cpp > trans.log
g++ -E main1.cpp > trans1.log
간단한 프로그램을 동작하는데 trans1.log 크기가 큰 것을 확인 할 수 있다.
#include <iostream>에 의한 치환 과정에서 iostream에서 참조하는 헤더들과 또 그 헤더들이 참조하는 헤더들이
중첩적인 과정을 통해서 번역 단위가 커지는 것을 확인 할 수 있다.
전처리 매크로의 위험
매크로는 단순한 텍스트 치환으로 동작하는데 c++의 의미론과 무관하게 동작한다.
// common.h
#define SIZE 10
// item.h
#define SIZE 100다음과 같이 같은 전처리 매크로 값에 충돌이 발생하고 cpp 파일에서 두 헤더를 참조한다고 할 때 순서를 어떻게 하느냐에 따라서 "SIZE" 값이 달라진다.
기호 중복 정의
c++에는 ODR이라는 용어가 있는데 One Definition Rule이다. 번역 단위나 프로그램에서 함수의 선언은 하나이어야 한다. c++에서는 해당 중복 정의를 회피하기 위해서 포함 가드(include guard)를 사용한다.
// header.h
// #pragma once
#ifndef FUNC_H
#define FUNC_H
void func1() {
#endif모듈의 장점
- 모듈은 단 한번만 도입되며 비용이 거의 없다.
- 모듈을 도입하는 순서에 따른 차이가 없다.
- 모듈에서는 기호 중복 정의 문제가 거의 발생하지 않는다.
- 모듈은 코드의 논리적 구조를 표현하는데 유리하다.
- 명시적으로 노출할 대상을 지정할 수 있다.
- 다수의 모듈을 모아서 하나의 논리적 패키지로 제공할 수 있다.
- 소스 코드를 인터페이스 부분과 구현 부분으로 분리할 필요가 없다.
모듈의 구조
컴파일러 별 모듈 파일
컴파일러 별로 모듈에 대한 확장자를 다르게 설정 하였다.
- MSVC의 경우 ixx 확장자를 모듈로 사용한다.
- Clang의 경우 cppm 확장자를 사용 했으나 최근에는 cpp를 사용한다.
- GCC의 경우 모듈 파일에 대해 특별한 확장자를 사용하지 않는다.
- module로 시작하는 구문과 모듈의 선언 사이에는 전역 모듈 조각이라는 공간이 존재한다.
- 전역 모듈 조각에는 아직 모듈화 되지 않은 헤더 파일을 추가 할 수 있다.
- 'export module xxx'은 모듈의 선언이다.
- 클라이언트는 선언된 모듈 이름을 통해서 모듈을 사용 할 수 있다.
- 모듈안에서 참조할 모듈을 import를 통해서 가져올 수 있다.
- 내보낼 모듈들은 export namespace로 선언된 공간에 선언한다.
- 내보내지 않을 선언들은 export를 포함하지 않고 선언한다.
module; // 전역 모듈 조각
#include <string> // 아직 모듈화 되지 않는 라이브러리 헤더
export module test; // 모듈 선언, 여기서 부터 모듈 시작
import test2 // 사용할 모듈
// 내부에서만 사용할 선언들
const char* _getName() { return "test"; }
// 외부에 노출할 선언들
export namespace test {
std::string name() { return std::string{ _getName() }; }
}모듈 인터페이스 단위와 모듈 구현 단위
모듈이 커지면 모듈을 하나의 모듈 인터페이스 단위와 하나 이상의 모듈 구현 단위로 분할 하는 것을 권장한다.
모듈 인터페이스
모듈 인터페이스에는 모듈 선언을 내보내는 선언이 있어야 한다. ("export module math")
모듈이 내보낼 함수들을 정의한다. 하나의 모듈에는 모듈 인터페이스는 하나이어야 한다.
module;
#include <string>
export module math;
export namespace math {
int add(int fir, int sec);
int sub(int fir, int sec);
class Vec {
public:
std::string getName();
};
}모듈 구현 단위
모듈 구현 단위에도 모듈 선언이 있어야 하지만 export는 붙이지 않는다. 하나의 모듈에 여러개의 모듈 구현 단위가 있을 수 있다.
// mathImplementationUnit.cpp
module;
#include <numeric>
#include <string>
module math;
namespace math {
int add(int fir, int sec) {
return fir + sec;
}
int sub(int fir, int sec) {
return fir - sec;
}
std::string Vec::getName() {
return std::string{ "Vec" };
}
}cpp에서 모듈 사용 예제
// main.cpp
import math;
#include <iostream>
int main()
{
math::Vec vec;
auto a = vec.getName();
std::cout << a << std::endl;
return 0;
}하위 모듈
모듈이 더욱 더 커지면 하위 모듈이나 모듈 분할이라는 방식으로 더 작은 단위로 관리 할수 있다.
아래 예제에서는 math를 math.math1, math.math2라는 하위 모듈로 나눠서 정의한다.
// mathModule.ixx
export module math;
export module math.math1;
export module math.math2;
// mathModule1.ixx
export module math.math1;
export int add(int fir, int sec) {
return fir + sec;
}
// mathModule2.ixx
export module math.math1;
export int sub(int fir, int sec) {
return fir - sec;
}사용자는 다음과 같이 사용 할 수 있다.
#include <iostream>
import math;
int main() {
cout << '\n';
cout << "add(3,4): " << add(3,4) << '\n';
cout << "sub(3,4): " << sub(3,4) << '\n';
}또는 직접 하위 모듈에 접근해서 사용 할 수도 있다.
// mathModuleClient1.cpp
// 하위 모듈을 직접 접근 할 수 있다.
#include <iostream>
import math.math1;
int main() {
cout << '\n';
cout << "add(3,4): " << add(3,4) << '\n';
}
헤더 단위
헤더 단위(header unit)란 전통적인 헤더에서 모듈로 넘어가기 위한 방법이다. 단순히 #include 지시문에서 import 지시자로 바꾸고 세미콜론(;)을 붙이면 된다.
#include <iostream> => import <iostream>;
#include "MyHeader.h" => import "MyHeader.h";이렇게 헤더 단위를 사용하면 컴파일러는 모듈에서 export 한것 처럼 처리하기 때문에 기존의 #include 보다 빠르ㅡ다.
헤더 단위의 단점
모든 헤더를 헤더 단위로 도입할 수 없다.
c++ 표준 라이브러리는 도입 가능하지만 C 헤더들은 도입 불가이다.
버그를 추적하기가 힘들다. (ODR 위반)
구성 요소간의 구분이 없고 적용이 깨지기 쉽다.
MSVC에서 STL 라이브러리를 헤더 단위로 사용해보기
msdn에서는 2가지 방법을 제시한다.
- STL 라이브러리의 헤더 단위 정적 라이브러리 만들기
- STL 헤더를 검색하고 헤더 단위로 컴파일 하는 방법
여기서는 간단한 2번째 방법으로 진행해본다.
프로젝트 옵션 설정
프로젝트 속성 페이지로 이동한다.
- 구성, 플랫폼을 모든 구성, 모든 플랫폼으로 수정한다.
- 구성 속성 -> C/C++ -> 일반의 아래 속성을 다음과 같이 변경한다.
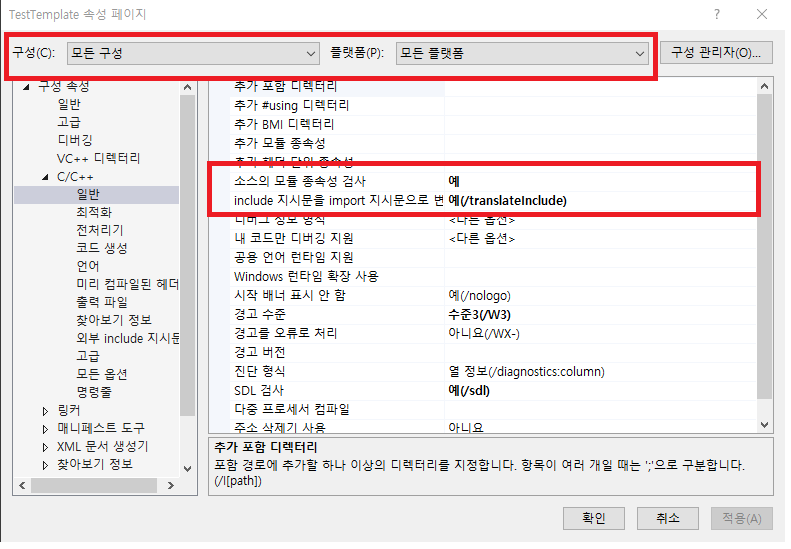
설정 후에 다음과 같이 입력후 빌드를 실행한다.
첫 실행시에 include 지시문으로 import 지시문으로 변환하는데 시간이 오래 걸린다.
import math;
import <iostream>;
int main()
{
std::cout << "import 빌드 완료" << std::endl;
return 0;
}'프로그래밍 언어 > C++' 카테고리의 다른 글
| C/C++ 예외상황에서의 포인터의 동작 (0) | 2022.12.17 |
|---|---|
| C++ if/switch statement with initializer (0) | 2022.12.11 |
| C언어로 객체지향 주 4개의 요소 (추상화,다형성,상속,캡슐화) 구현하기 (0) | 2022.11.26 |
| C++ call by value, call by reference (0) | 2022.11.17 |
| C++ (template, auto, decltype) 타입 추론 Universal reference (0) | 2022.11.14 |