
왜 해야할까?
Direct3D 11 이전의 그래픽스 API는 단일 스레드에서 실행되는 것을 중점으로 두고 설계되었다. 암시적인 동기화 지점이 존재해서 API를 호출하고 난 다음 GPU의 처리가 완료 되었을 때 이후의 코드가 실행된다,

문제는 이렇게 순서를 맞춰서 진행하는 방식은 CPU와 GPU를 최대로 활용하지 못하는 점이다. CPU 계산 중에 GPU는 제출된 명령이 없기 때문에 아무런 일도 하지않고 CPU의 처리를 기다리게 되고 렌더링 중에는 동기화 지점으로 인해서 CPU는 GPU의 처리가 끝날 때 까지 기다리게 된다.

따라서 CPU와 GPU가 비효율적으로 사용되지 않도록 스레드를 분리하여 렌더링과 CPU 계산이 동시에 이뤄지도록 해야한다.

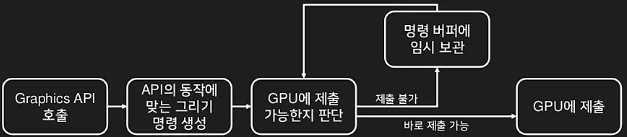
GPU가 무언가를 그리도록 요청하기 위해서 그래픽스 API를 호출하면 다음과 같은 순서로 그리기 명령 (Rendering commmand)이 생성되어 GPU에게 제출된다.
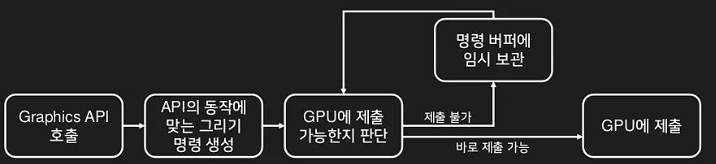
그리기 명령을 생성하고 이를 제출하는 과정은 CPU를 통해서 처리된다, 그리고 이 과정이 CPU에서 처리된다면 이 부분을 여러 스레드를 통해서 빠르게 생성한 후 GPU에 제출할 수 있도록 개선 할 수 있다.

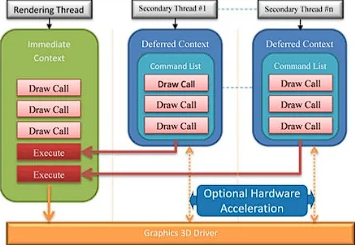
Data Race가 무엇인가?
데이터 경합은 멀티 스레드 프로그래밍에서 피할 수 없는 이슈다. 스레드 간의 경합에 더해 GPU와의 경합도 발생한다 따라서 이런 데이터 경합이 발생하지 않도록 전략을 세워야한다. 아래는 예시다.
스레드간 경합 문제
다음과 같이 게임 로직과 렌더링이 별도의 스레드에서 이뤄지고 있는 상황이고 여기에는 화면에 그려질 수 있는 게임 오브젝트 A가 있다.

게임 스레드는 A에 대한 게임 로직을 수행하고 렌더링 스레드에서는 A를 화면에 그린다. 즉 A는 두 개의 스레드가 공유하고 있는 자원이다.

만약 게임 로직에 따라서 A라는 오브젝트가 삭제되는데 렌더링 스레드가 A를 참고하고 있는 상황이라면 문제가 된다 따라서 참조하지 않을 때 까지 A의 삭제는 유보돼야 한다.

GPU와의 경합 문제
GPU에서 A를 그리기 위한 셰이더 코드가 실행되고 있는 경우다. GPU는 그래픽 카드 메모리로 전송된 물체의 위치나 재질을 참조하여 물체를 어디에 어떻게 그려야 할지를 결정한다.

이런 상황에서 CPU가 A의 상태를 업데이트하고 이 결과를 그래픽 카드로 메모리로 전송하면 A를 그리고 있는 도중에 참조하고 있던 데이터의 값이 변경될 수 있다.

Data Race 경합 해결
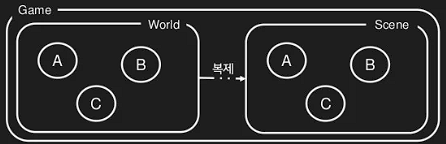
우선 게임의 세상을 2가지로 나눈다. 게임의 세상을 게임 스레드를 위한 World와 렌더링 스레드를 위한 Scene으로 나눈다.

Scene은 World의 복제본인데 렌더링에 관련된 데이터에만 복사해 온 렌더링을 위한 세상이다 그리고 게임 스레드는 World만을 수정하고 렌더링 스레드는 Scene만을 수정하도록 엄격하게 제한한다.
다음은 특정 스레드에서만 수행되야 하는 코드가 해당 스레드에서 실행되는지 검사하여 이런 제약을 준수할 수 있도록 하는 예시다.
void Scene::AddPrimitive( PrimitiveComponent* primitive )
{
PrimitiveProxy* proxy = primitive->CreateProxy();
primitive->m_sceneProxy = proxy;
if ( proxy == nullptr )
{
return;
}
PrimitiveSceneInfo* primitiveSceneInfo = new PrimitiveSceneInfo( primitive, *this );
proxy->m_primitiveSceneInfo = primitiveSceneInfo;
struct AddPrimitiveSceneInfoParam
{
Matrix m_worldTransform;
BoxSphereBounds m_worldBounds;
BoxSphereBounds m_localBounds;
};
AddPrimitiveSceneInfoParam param = {
primitive->GetRenderMatrix(),
primitive->Bounds(),
primitive->CalcBounds( Matrix::Identity ),
};
EnqueueRenderTask(
[this, param, primitiveSceneInfo]()
{
PrimitiveProxy* sceneProxy = primitiveSceneInfo->Proxy();
sceneProxy->WorldTransform() = param.m_worldTransform;
sceneProxy->Bounds() = param.m_worldBounds;
sceneProxy->LocalBounds() = param.m_localBounds;
sceneProxy->CreateRenderData();
AddPrimitiveSceneInfo( primitiveSceneInfo );
} );
}bool IsInRenderThread()
{
return GetInterface<ITaskScheduler>()->GetThisThreadType() == ThreadType::RenderThread;
}size_t TaskScheduler::GetThisThreadType() const
{
std::thread::id thisThreadId = std::this_thread::get_id();
for ( size_t i = 0; i < m_workerCount; ++i )
{
if ( m_workerid[i] == thisThreadId )
{
return i;
}
}
return m_workerCount;
}
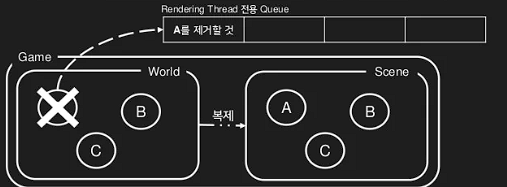
다음과 같이 게임 스레드가 월드의 A를 삭제해도 Scene에는 영향이 없기 때문에 삭제된 오브젝트에 접근해서 문제가 발생하는 경우를 방지할 수 있다. 그럼 Scene의 A는 어떻게 삭제해야 될까?
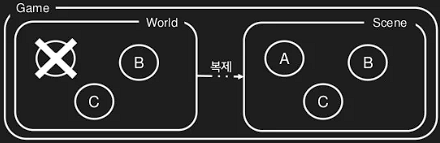
스레드에 대한 요청은 스레드의 전용 큐를 통해서 이뤄진다. A가 삭제 될 경우 게임 스레드는 A에 대한 삭제 요청을 렌더링 스레드 큐에 집어넣고 렌더링 스레드는 적절한 때에 큐의 요청을 처리하게 된다.
void Scene::RemovePrimitive( PrimitiveComponent* primitive )
{
PrimitiveProxy* proxy = primitive->m_sceneProxy;
if ( proxy )
{
PrimitiveSceneInfo* primitiveSceneInfo = proxy->m_primitiveSceneInfo;
primitive->m_sceneProxy = nullptr;
EnqueueRenderTask(
[this, primitiveSceneInfo]()
{
RemovePrimitiveSceneInfo( primitiveSceneInfo );
} );
}
}EnqueueRenderTask() 함수는 렌더링 스레드에 태스크를 제출하는 함수이며 렌더링 스레드에서 호출한 경우에는 해당 테스크를 바로 실행한다.
template <typename Lambda>
void EnqueueRenderTask( Lambda lambda )
{
if ( IsInRenderThread() )
{
lambda();
}
else
{
auto* task = Task<LambdaTask<Lambda>>::Create( WorkerAffinityMask<ThreadType::RenderThread>(), lambda );
EnqueueRenderTask( static_cast<TaskBase*>( task ) );
}
}void EnqueueRenderTask( TaskBase* task )
{
assert( task->WorkerAffinity() == WorkerAffinityMask<ThreadType::RenderThread>() );
auto taskScheduler = static_cast<TaskSchedulerImpl*>( GetInterface<ITaskScheduler>() );
TaskHandle taskGroup = taskScheduler->GetExclusiveTaskGroup( ThreadType::RenderThread );
taskGroup.AddTask( task );
[[maybe_unused]] bool success = taskScheduler->Run( taskGroup );
assert( success );
}전용 큐는 각 스레드당 하나로 제한하였는데 이는 다른 스레드의 요청이 순서를 지켜 실행해야 하기 때문이다.
A 물체의 위치 업데이트 > 게임 장면 그리기 > A 물체의 삭제와 같은 요청이 순서가 보장되지 않아
A 물체의 삭제 > A 물체의 위치 업데이트 > 게임 장면 그리기와 같은 순서로 실행되면 의도하지 않은 동작이기 때문이다 따라서 이러한 방법은 게임 로직과 렌더링을 마치 클라이언트 서버 모델과 유사하게 다루게 한다.
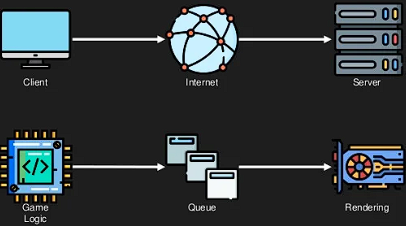
결합 해결 코드
새로 생성된 게임 물체는 World 클래스의 SpawnObject() 함수를 통해서 게임 세상에 추가된다.
void World::SpawnObject( CGameLogic& gameLogic, Owner<CGameObject*> object )
{
object->Initialize( gameLogic, *this );
object->SetID( m_gameObjects.size() );
m_gameObjects.emplace_back( object );
}World 클래스는 게임 스레드에서 참조할 수 있는 게임 물체인 CGameObject 객체들을 보관하고 있으며 World와 쌍을 이루는 렌더링 스레드 전용 세상인 Scene을 참조하고 있다.
std::vector<std::unique_ptr<CGameObject>> m_gameObjects;Scene 클래스는 World와 유사하게 렌더링 스레드에서 참조할 수 있는 게임 물체인 PrimitiveSceneInfo 객체를 보관하고 있으며 이 객체는 게임 스레드의 요청에 의해 Scene에 추가되거나 삭제된다.
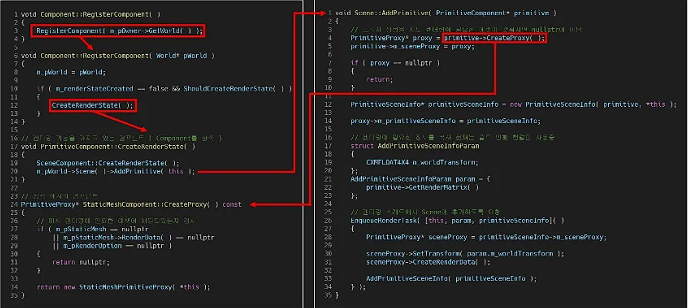
SparseArray<PrimitiveSceneInfo*> m_primitives;게임 스레드는 렌더링 할 필요가 있는 경우에 SpawnObject 함수에서 오브젝트를 초기화 할 때 필요한 에셋이 모두 갖춰졌는지 판단하여 렌더링 스레드에 PrimitiveSceneInfo 객체의 추가를 요청한다.
void CGameObject::Initialize( CGameLogic& gameLogic, World& world )
{
m_pWorld = &world;
for ( std::unique_ptr<Component>& component : m_components )
{
component->RegisterComponent();
}
RegisterThinkFunction();
for ( std::unique_ptr<Component>& component : m_components )
{
component->RegisterThinkFunction();
}
}
Rendering Command 생성
그리기 작업은 때때로 순서가 중요한 경우가 있다. 예를 들면 반투명 물체와 같이 카메라에 먼 순서부터 물체를 그려야 하는 경우 Z Sorting로 순서를 보장하기 위해서 어떻게 병렬화를 하는 것이 좋은지 고려해야 한다.
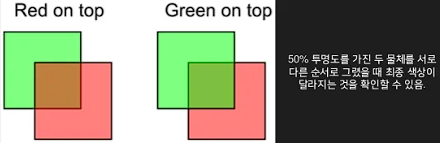
여기서는 전형적인 Fork-join 모델을 사용하여 그려야 할 전체 리스트를 작업 스레드의 개수로 나눠 처리하였다.
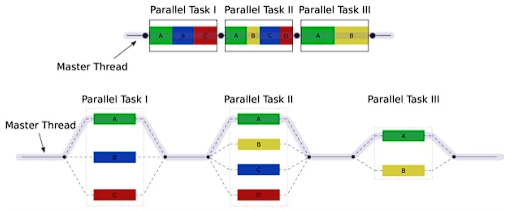
깊이 렌더링이나 그림자 맵 렌더링과 같이 Z 버퍼를 사용할 수 있는 상황에서는 그리기 순서가 그리 중요하지 않기 때문에 다른 병렬화 전략을 취할 수 있다. 예를 들면 Join시 모든 태스크의 완료를 기다리지 않고 완료된 태스크부터 GPU에 명령을 제출할 수도 있다. 현재 코드는 모든 스레드를 기다리도록 구현되어 있지만 모든 상황에 알맞은 방법은 아니다.
Direct3D11 Deferred Context
한 가지 특이점이 존재한다. GPU에 명령을 즉시 제출하는 Immediate Context는 일종의 상태 머신과 같아 렌더링 파이프라인의 상태를 바꾸는 명령 (RSSetState, OMSetBlendState 등)을 통해 상태가 변경되면 해당 상태가 계속 유지되었다. 예를 들어 깊이 테스트를 끄도록 했다면 다시 깊이 테스트를 키는 명령을 제출하기 전까지 해당 상태가 유지되어 다음 그리기에도 영향을 미친다. 하지만 Deferred Context의 경우는 생성 시 Immediate Context의 파이프라인 상태와 상관없는 기본 상태로 생성되고 Immediate Context에 제출해도 파이프라인 상태를 변경시키지 않는다.
Q. 이전 그리기에서 Immediate Context를 통해 뷰포트를 설정한 다음에 DeferredContext를 통해 기록된 그리기 명령을 Immediate Context에 제출했을 때 해당 명령들은 Immediate Context에 설정된 뷰포트의 영향을 받을까?
A. 영향을 받지 않는다 그리고 Deferred Context에 뷰포트를 설정하는 명령을 기록하지 않았다면 Deferred Context는 기본 설정으로 생성되기 때문에 정상적으로 렌더링이 이뤄지지 않는다.
Q. Deferred Context 2개 D1, D2에 각각 명령을 기록하고 D1 -> D2의 순서로 Immediate Context에 제출하였다. D1의 파이프라인 상태는 D2에 영향을 미칠까?
A. 영향을 미치지 않는다. D2에 기록된 명령들은 D2의 상태에만 영향을 받는다.
Deferred Context에 명령을 기록할 때는 Viewport, Scissor rectangle, Render Target View와 같은 상태를 매번 설정해줘야 한다.
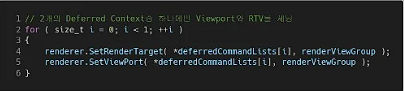
누락시 좌측과 같은 이미지를 얻게된다.

그리기 명령을 병렬로 제출하는 ParallelCommitDrawSnapshot 함수이다.
// 코드
실제로 명령을 기록하는 CommitDrawSpashotTask
//
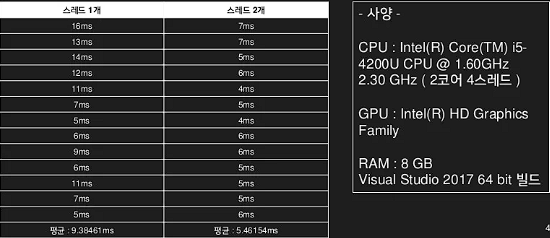
싱글 스레드로 제출한 경우와 2개의 스레드를 통해서 명령을 제출하는데 걸린 시간의 비교표이다.
Dynamic Instancing
인스턴싱 (Instancing)은 동일한 물체 여러 개를 하나의 드로우 콜로 한 번에 그리는 방식이다.
GPU가 일을 하기 위해서는 CPU로 부터의 명령이 필요한데 명령을 제출하는데 비교적 많은 시간이 걸린다.
여러 물체를 그리는 상황을 간단하게 표현해보면 다음과 같이 오버 헤드가 매 드로우 콜마다 발생한다. 인스턴싱은 동일한 물체들을 한 번에 그려 드로우 콜 마다 발생하는 오버헤드를 줄인다.

동일한 물체의 정의
다이나믹 인스턴싱은 장면에 추가된 물체를 자동으로 분류해서 동일한 물체가 여러 개 있는 경우 자동으로 인스턴싱을 통해 물체를 그리는 방식으로 Auto Instancing이라고 한다.
아래처럼 같은 모양의 구들도 서로 다른 위치에 그려야하기 때문에 한 번에 그려지는 물체에도 서로 다른 부분이 존재한다.

물체에 따라서 다를 수 있는 부분은 대표적으로 물체의 위기가 있을 수 있고 본 애니메이션이 필요한 메시라면 본의 행렬 값 등이 있다. 이와 같이 똥일한 물체 간에 어떤 값이 서로 다를 수 있는지는 경우에 따라 다르게 규정할 수 있다. 현재 프로그램에는 고정된 모양의 스태틱 메시만 존재하는데 위치, 크기, 회전 변환을 제외하고 모든 값이 (재질, 메시 모양 등) 같아야 동일한 물체로 취급하고 있다.
물체간 서로 다른 정보는 인스턴싱 중에 참조할 수 있도록 미리 그래픽 메모리에 전송해야 한다. 이 정보는 렌더링 스레드에서 Scene에 물체를 추가할 때나 관련 데이터 변경 시 그래픽 메모리로 업로드하고 셰이더 코드에서는 인풋 어셈블러를 통해 인스턴스 데이터로 전달된 인덱스 값을 통해서 접근하도록 한다.
// hlsl VS_OUTPUT main
// struct PrimitiveSceneData
DrawSnapshot
동일한 물체의 기준을 정했다면 이제 물체를 분류하기 위한 모든 정보를 모아야 한다. DrawSnapshot은 분류를 위한 클래스로 어떤 물체를 그릴 때의 파이프라인 상태에 대한 스납샷이다.

// 코드에서는 다음과 같다 DrawSnapshot 클래스 참조
// CommitDrawSnapshot 함수
이제 동일 물체끼리 분류하는 작업만이 남았다. 이것은 DrawSnapshot을 정렬하는 것으로 해결할 수 있다. 다만 DrawSnapshot은 모든 정보를 담고 있기 때문에 클래스의 크기가 매우 크다. 64bit에서는 기본 크기만 520Byte에 달한다 그리고 셰이더에 설정될 모든 리소스의 참조는 셰이더에 따라 가변적일 수 있기 때문에 더 늘어 날 수 있다. 따라서 DrawSnapShot 자체를 정렬 중에 비교하는 것은 좋지 않다.
이를 해결하기 위해서 DrawSnapshot에 아이디를 부여하였다.
// CachedDrawSnapshotBucket 클래스
출처 : https://www.slideshare.net/xtozero/multithreaded-rendering
소스코드 : https://github.com/xtozero/SSR/tree/multi-thread
'그래픽스 > 공통' 카테고리의 다른 글
| 셰이더란? (Shader) (0) | 2022.10.30 |
|---|---|
| 그래픽스 API 정의와 비교 분석 (0) | 2022.09.04 |
| 폴리곤 메쉬 (Polygon Mesh) (0) | 2022.08.06 |
| 사원수 (Quaternion : 쿼터니언) (0) | 2022.07.25 |
| 짐벌락 & 오일러 각 (Gimbal Lock & Euler Angle) (0) | 2022.07.25 |