UNION
다른 데이터를 합쳐서 보여주는 것이다.
syntax :
SELECT column1, column2, column3
FROM table1
UNION
SELECT column1, column2, column3 FROM table2
UNION
SELECT column1, column2, column3
FROM table3
;
일반적으로 UNION 이라고 선언하면 UNION DISTINCT 라고 보면 된다 즉, 중복된 데이터를 제외하고 데이터를 합침. 위의 예시에서 UNION 대신 UNION DISTINCT 라고 해도 결과는 같음.
UNION 하는 컬럼의 명이 같지 않아도 되나,
SELECT하는 컬럼의 수와 각각의 데이터형의 순서 동일해야 함.
만약, 첫번째 테이블에서 int, string, string 으로 컬럼을 추출한다면,
UNION 되는 테이블에서도 int, string, string의 컬럼을 추출해야 함.
만약, 첫번째 테이블에서 컬럼을 세개 추출하면,
UNION 되는 테이블에서도 컬럼을 세개 추출해야 함.
여러개를 UNION 할 경우,
SELECT ...
FROM table1
UNION
SELECT ...
FROM table2
UNION
SELECT ...
FROM table3
...
와 같이 계속해서 붙여주면 됨.
예를 들어서, 음원 사이트를 만든다고 할 때, 국내 음악 (domestics)과 국외 음악 (overseas)을 별개의 테이블로 관리한다고 가정

만약 이 두 테이블의 모든 signer와 title의 목록을 보고 싶을 때
SELECT singer, title
FROM domestics
UNION
SELECT singer, title
FROM overseas;이렇게 선언하면 된다, 그러면 중복된 결과를 제외한 모든 리스트가 출력됨
만약 데이터가 다음과 같이 있다고 가정
SELECT singer, title
FROM domestics
UNION
SELECT singer, title
FROM overseas;했을 경우, 다음과 같은 데이터가 출력된다
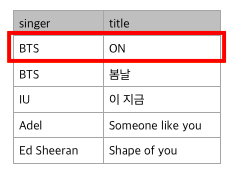
중복된 BTS의 ON이 두개이기 때문에 하나는 제외되며 5개의 데이터가 출력.
UNION DISTINCT를 해도 결과는 같음. 기본적으로 UNION은 UNION DISTINCT의 의미를 가짐
UNION ALL
UNION 연산에서 중복된 데이터를 제외하지 않고 모든 데이터를 출력
SELECT column1,column2,column3
FROM table1
UNION ALL
SELECT column1,column2,column3
FROM table2
UNION ALL
SELECT column1,column2,column3
FROM table3
;
UNION ALL도 UNION과 마찬가지로 SELECT하는 컬럼의 명이 같지 않아도 되나, SELECT하는 컬럼의 수와 각각의 데이터형의 순서 동일해야함.
위의 예시를 그대로 활용
SELECT singer,title
FROM domestics
UNION ALL
SELECT singer,title
FROM overseas;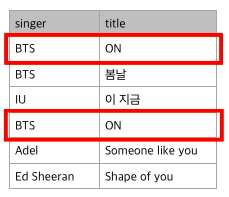
중복 데이터도 모두 출력되는 것을 확인할 수 있음
중복 여부는 추출되는 컬럼이 모두 동일한 경우에 중복으로 판단한다, 즉 singer, title을 추출하기 때문에 이 두가지 정보가 모두 일치해야 중복된 데이터로 판단. "BTS의 봄날" 이라는 데이터는 domestics 내에는 있으나 overseas에는 없기 때문에 중복이 되지않음. 만약 singer만 추출한다고 하면
SELECT singer
FROM domestics
UNION
SELECT singer
FROM overseas;
이렇게 했을 경우, BTS는 세번으로 중복(domestics 2번, overseas 1번)되기 때문에 한번만 출력되어 총 4개의 데이터만 출력

UNION ALL일 경우 6개의 데이터 모두 출력
MySQL에서의 UNION 처리 과정
1. 최종 UNION [ALL | DISTINCT] 결과에 적합한 임시 테이블을 메모리 테이블로 생성
2. UNION 또는 UNION DISTINCT 의 경우, Temporary 테이블의 모든 컬럼으로 Unique Hash 인덱스 생성
3. 서브쿼리1 실행 후 결과를 임시 테이블에 복사
4. 서브쿼리2 실행 후 결과를 임시 테이블에 복사
5. 만약 3,4번 과정에서 임시 테이블이 특정 사이즈 이상으로 커지면 임시 테이블을 Disk Temporary 테이블로 변경 (이때 Unique Hash 인덱스는 Unique B-Tree 인덱스로 변경됨)
6. 임시 테이블을 읽어서 Client에 결과 전송
7. 임시 테이블 삭제
'프로그래밍 언어 > SQL' 카테고리의 다른 글
| [SQL] 보안, 권한 부여 grant, revoke, role (0) | 2024.10.15 |
|---|---|
| [SQL] CASE WHEN 조건 여러개 (다중 조건, 다중 칼럼) (0) | 2024.08.21 |
| [SQL] CASE WHEN 표현식 사용법 (DECODE, IF) (0) | 2024.08.21 |
| [SQL] 별칭 (Alias) 활용하기 (0) | 2024.08.15 |
| [SQL] 피봇에 대해 알아보자 (PIVOT, UNPIVOT) (0) | 2024.08.12 |