![[SQL] 정규화(Normalization)와 반정규화(De-Normalization)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbRWsMh%2FbtsIQx2of9z%2FCm5gA5bN9oonJLf656j8uk%2Fimg.png)
정규화란?
- 정규화는 데이터의 일관성, 최소한의 데이터 중복, 최소한의 데이터 유연성을 위한 방법이며 데이터를 분해하는 과정이다.
- 정규화된 모델은 테이블이 분해된다. 테이블이 분해되면 직원 테이블과 부서 테이블 간에 부서코드로 조인(join)을 수행하며 하나의 합집합으로 만들 수 있다.
- 정규화를 하면 불필요한 데이터를 입력하지 않아도 되기 때문에 중복 데이터가 제거된다.
절차

문제점
- 정규화는 데이터 조회(select) 시에 조인(join)을 유발하기 때문에 CPU와 메모리를 많이 사용한다.
- 아래 코드를 프로그램화 한다면 중첩된 루프(Nested Loop)를 사용해야 한다.
[ANSI JOIN}
select 사원번호, 부서코드, 부서명, 이름, 전화번호, 주소
from 직원, 부서
where 직원.부서코드 = 부서.부서코드;
select 사원번호, 부서코드, 부서명, 이름, 전화번호, 주소
from 직원 inner join 부서 on직원.부서코드=부서.부서코드;정규화를 사용한 성능 튜닝
- 조인으로 인하여 성능이 저하되는 문제를 반정규화로 해결할 수 있다.
- 반정규화는 데이터를 중복시키기 때문에 또 다른 문제점을 발생시킨다.
반정규화란?
- 데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법이다.
- 반정규화는 조회(select) 속도를 향상시키지만, 데이터 모델의 유연성은 낮아진다.
수행하는 이유
- 정규화에 충실하여 종속성, 활용성은 향상 되었지만 수행속도가 느려진 경우
- 다량의 범위를 자주 처리해야하는 경우
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
절차

클러스터링 인덱스라는 것은 인덱스 정보를 저장할 때, 물리적으로 정렬해서 저장하는 방법이다. 따라서 조회 시 인접 블록을 연속적으로 읽기 때문에 성능이 향상된다.
기법
계산된 컬럼 추가
- 배치 프로그램으로 총판매액, 평균잔고, 계좌평가를 미리 계산하고 그 결과를 특정 칼럼에 추가한다.
테이블 수직 분할
- 하나의 테이블의 두 개 이상의 테이블로 분할한다. 즉, 칼럼을 분할하여 새로운 테이블을 만드는 것이다.
테이블 수평분할
- 하나의 테이블에 있는 값을 기준으로 테이블을 분할하는 방법이다.
[Partition]
- 데이터베이스에서 파티션을 사용하여 테이블을 분할할 수 있다.
- 파티션을 사용하면 논리적으로는 하나의 테이블이지만, 여러 개의 데이터 파일에 분산되어 저장된다.
- Range Partition: 데이터 값의 범위를 기준으로 파티션을 수행한다.
- List Partition: 특정한 값을 지정하여 파티션을 수행한다.
- Hash Partition: 해시 함수를 적용하여 파티션을 수행한다.
- Composite Partition: 범위와 해시를 복합적으로 사용하여 파티션을 수행한다.테이블 병합
- 1:1 관계의 테이블을 하나의 테이블로 병합해서 성능을 향상시킨다.
- 1:N 관계의 테이블을 병합하여 성능을 향상시킨다. 하지만 많은 양의 데이터 중복이 발생한다.
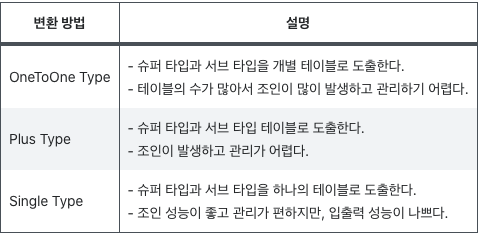
- 슈퍼 타입과 서브 타입 관계가 발생하면 테이블을 통합하여 성능을 향상시킨다.
[Super type과 Sub type]
- 슈퍼타입과 서브타입의 관계는 배타적 관계와 포괄적 관계가 있는데,
배타적 관계는 고객이 개인이거나 법인고객인 경우를 의미한다.
- 포괄적인 관계는 고객이 개인고객일 수도 있고 법인고객일 수도 있는 것이다.슈퍼 타입 및 서브 타입 변환 방법
'프로그래밍 언어 > SQL' 카테고리의 다른 글
| [SQL] 데이터 타입 CHAR, VARCHAR (0) | 2024.08.06 |
|---|---|
| [SQL] 인덱스 힌트 / 옵티마이저 힌트 사용 방법 (주석, 튜닝) (0) | 2024.08.06 |
| [SQL] GROUP BY 절 사용법 (그룹별 집계) (0) | 2024.07.29 |
| [SQL] INSERT 문 사용법 3가지 (데이터 입력) (0) | 2024.07.29 |
| [DB] 트랜잭션 (Transaction) 4가지 특성 (0) | 2024.07.15 |