
컴퓨터가 이해하는 언어는 0과 1(1bit)이다. 2진수로 데이터를 처리한다.
컴퓨터는 전기신호를 받아들이므로 전기의 OFF, ON 두 가지 상태(0과 1)로 모든 걸 표현하기 때문이다.
0과 1의 두 가지 상태를 나타내는 단위를 bit라고 한다.

그러나 1bit만으로는 표현할 수 있는 게 0, 1 단 두 개뿐이니, 더 큰 수를 표현하기 위해 8개의 bit를 묶어서 1byte를 사용한다. 컴퓨터가 데이터를 저장하는 최소 단위가 바로 이 byte다.
1byte는 8개의 bit니까 2의 8제곱, 즉 0~255(256개)의 데이터를 저장할 수 있다.
중요한 것은 더 큰 수를 표현할 수 있게 되었더라도 컴퓨터가 인식하는 것은 숫자라는 점이다.
컴퓨터는 0과 1 이외에는 아무것도 인식할 수 없기 때문이다.
그렇다면 어떻게 컴퓨터가 문자를 입력받고 출력할 수 있는 것일까? 정답은 ASCII Code에 있다.
ASCII란, 'American Standard Code for Information Interchange'의 약자다.
문자에 대해 각각의 번호를 지정하여 관리하고 있는 집합체이며, 가장 기초가 되는 문자 코드다.
아래 그림처럼 문자들이 숫자에 매핑되어 있다.
ASCII Code는 0부터 127까지(2의 7제곱, 7bit) 표현할 수 있다. 즉, 1byte 내에서 모든 걸 다 표현할 수 있다는 뜻이다.
컴퓨터의 키보드에 있는 알파벳, 숫자, 특수문자들은 ASCII Code 안에서 모두 처리할 수 있다.
유럽어와 추가 특수문자(「 」 +)를 표현할 수 있는 Code까지 합치면 128개의 데이터가 추가된다.
따라서 우리는 총 128 + 128 = 256개(8bit)의 데이터를 표현할 수 있는 확장 ASCII Code를 사용한다.
위의 표에서 생략된 제어문자 내용을 좀더 자세히 보면 아래와 같다.
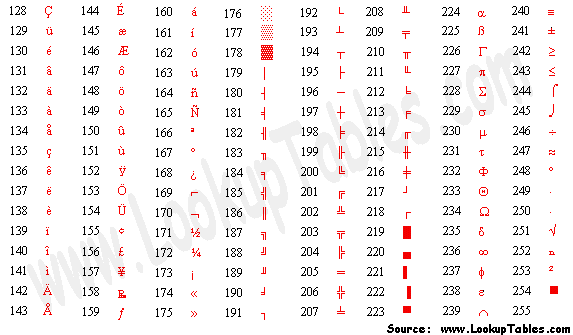
ASCII Code의 0번(decimal)에 해당하는 NUL은 문자열의 끝을 나타낼 때 사용한다.
7번은 alert(경고음)을 만들 때 사용한다.
10번은 Carriage return(줄바꿈)을 나타내며 Enter키와 같다.
32번은 Space(공백), 27번은 ESC를 의미한다.
문자를 입력하면 숫자로 컴퓨터에게 전달되고, 컴퓨터는 전달받은 숫자의 아스키코드 테이블을 뒤져서 해당하는 문자를 그려준다.

예를 들어 키보드에서 'B'를 누르면, 컴퓨터에는 특정 전압이 전달되고, 이 전압을 bit로 표현하면 1000010과 같다.
이 비트값을 대문자 'B'에 해당하는 ASCII 값인 66(0x42)로 변환한다.
이렇게 변환한 디지털신호는 데이터버스를 통해 컴퓨터로 전달되고, 화면에 그려주는 것이다.
문자 'B'로 출력할지 숫자 66(0x42)로 출력할지는 프로그래머의 요청에 따라 처리한다.
'5', '3'처럼 문자로 사용하여 문자와 숫자가 혼합된 곳에 활용한다.

숫자를 문자로 변환할 수 있다면 아래처럼 문자도 숫자로 변환할 수 있다.
알파벳 'A'와 'a', 즉 대소문자가 32의 간격을 두고 있고, '0'이 ASCII Code 48번이라는 점을 기억하면 좋다.
// C언어 코드
int main(void)
{
printf("a - 32 = %c (%d)\n", 'a'-32, 'a'-32);
printf("'1' - '0' = %d\n", '1'-'0');
return (0);
}
// 실행 결과
a - 32 = A (65)
'1' - '0' = 1
키보드에서 'A'를 입력하면 컴퓨터는 ASCII Code 숫자 65로 저장하고,
프로그래밍 언어에서 %c로 꺼내면 char, %d로 꺼내면 decimal 형태로 표현해준다.
문자를 표현하여 통신하기 위해 만들어진 것이 ASCII Code 개념이며, 한 문자를 1byte로 다룬다.
한 문자를 표현하는 경우의 수가 256(2의 8제곱)이라는 것이다.
한편 한국어, 일본어, 중국어 등 모음과 자음이 분리된 보다 복잡한 언어는 1byte의 ASCII Table로 처리할 수 없다.
한글은 자음과 모음의 조합 개수만 해도 128개를 넘는다.
그래서 전세계 언어를 표현할 수 있는 Encoding Table, 즉 Unicode 가 만들어졌다.
Unicode란 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이며, 유니코드 협회(Unicode Consortium)가 제정한다.
Unicode는 문자당 2byte다. 2의 16제곱으로 65,536개의 문자를 표현할 수 있다.
따라서 Unicode는 ASCII Code를 포용할 수 있다.
Unicode에는 ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자를 처리하기 위한 알고리즘 등이 포함되어 있다.
일례로 C/C++에서 char가 1byte인 것과 달리 Java에서 char가 2byte인 이유는, 자바에서는 문자를 2byte로 표준화된 Unicode 체계를 사용하기 때문이다. 추후 UTF-8 등 유니코드 인코딩 시스템을 알아볼 일이 많이 생길 것이다.
'CS > OS & 하드웨어' 카테고리의 다른 글
| 세그멘테이션 (Segmentation) 오류 (0) | 2023.10.23 |
|---|---|
| 세그멘테이션(Segmentation)이란? 세그멘테이션 vs 페이징 (0) | 2023.10.23 |
| 프로그래밍 언어와 빌드 과정 [Build Process] (0) | 2023.09.23 |
| 아스키코드, 유니코드, UTF-8의 차이 (0) | 2023.09.10 |
| 메모리 (RAM) 구조 (0) | 2023.08.28 |