![[C++] STL 연관 컨테이너(associative container), set, multiset](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb3sRCX%2FbtsqYPL9gcT%2FTE4zq154iekpeeRaoLpOvk%2Fimg.png)
set 세트
set 컨테이너는 요소가 그 값에 따라 정렬되는 형태이다 즉, key라 불리는 원소(value)의 집합이다. 또한 이 원소들에 중복을 허용하지 않는다는 것이 특징이다.

#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> is;
is.insert(55);
is.insert(7);
is.insert(23);
is.insert(61);
is.insert(7);
is.insert(9);
is.insert(58);
set<int>::iterator it;
for(it = is.begin(); it != is.end(); it++) {
cout << *it << " ";
}
cout << endl;
return 0;
}
결과값
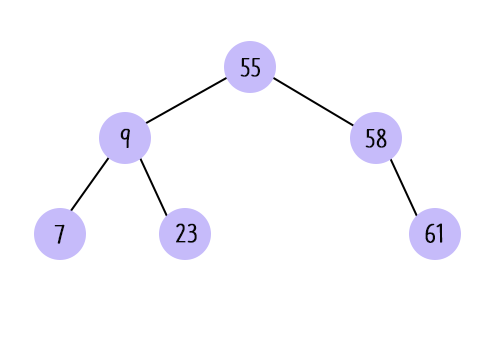
7 9 23 55 58 61그냥 제멋대로 insert를 해도 알아서 정렬이 된다.
실제 트리구조는 항상 균형 이진 트리로 구성된다.
이 구조가 왜 이렇게 되는지 알아보기전에 set의 멤버함수 기능중 하나를 더 알아보겠다.
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> is;
is.insert(55);
is.insert(7);
is.insert(23);
is.insert(61);
is.insert(7);
is.insert(9);
is.insert(58);
set<int>::iterator it;
for(it = is.begin(); it != is.end(); it++) {
cout << *it << " ";
}
cout << endl;
it = is.find(20);
if(it == is.end()){
cout << "not found" << endl;
}else {
cout << *it << " found" << endl;
}
it = is.find(7);
if(it == is.end()){
cout << "not found" << endl;
}else {
cout << *it << " found" << endl;
}
return 0;
}
결과)
7 9 23 55 58 61
not found
7 foundfind 함수는 set의 원소 중에 어떤 값이 있는지 찾아주는 함수다. 값이 존재하면 해당 값의 위치 없으면 마지막 인덱스를 반환한다. 이런건 시퀀스 컨테이너에도 있지만 차이 점이 있다면 실제로 동작하는 함수들의 시간복잡도다. 먼저 set은 insert 할 때 정렬이 되어 삽입된다. 즉, 원소를 추가하는 작업이 log N의 시간복잡도를 가지고 있다. 또한, find를 할 때도 정렬이 되어있는 트리구조이기 때문에 찾는 시간복잡도 또한 log N을 갖는다.
|
iter = set.begin()
|
set의 첫 번째 요소를 주소 지정하는 반복자를 반환.
|
|
set.clear()
|
set의 모든 요소를 지운다.
|
|
n = set.count(key)
|
키가 매개 변수로 지정된 키와 일치하는 set의 요소 수를 반환.
|
|
set.emplace(n)
|
생성된 요소 n을 set에 삽입.
|
|
set.emplace_hint(iter, n)
|
배치 힌트를 사용하여 생성된 요소 n을 해당 위치 set에 삽입.
|
|
set.empty()
|
set가 비어 있는지 여부를 테스트.
|
|
iter = set.end()
|
set에서 마지막 요소 다음에 나오는 위치를 주소 지정하는 반복자를 반환.
|
|
pair = set.equal_range(n)
|
지정된 키보다 더 큰 키를 가진 set의 첫 번째 요소와 지정된 키보다 더 크거나 같은 키를 가진 set의 첫 번째 요소에 반복자의 쌍을 각각 반환.
|
|
n = set.erase(key)
iter = set.erase(iter)
iter = set.erase(iter_begin, iter_end)
|
지정된 위치에서 set의 요소 또는 요소의 범위를 제거하거나 지정된 키와 일치하는 요소를 제거.
|
|
iter = set.find(key)
|
지정된 키와 같은 키를 가진 set 내 요소의 위치를 가리키는 반복자를 반환.
|
|
pair = set.insert(key)
iter = set.insert(iter, key)
set.insert(iter_begin, iter_end)
|
set에 요소 또는 요소의 범위를 삽입.
|
|
pred = set.key_comp()
|
set에서 키를 정렬하기 위해 사용하는 비교 개체의 복사본을 검색.
|
|
iter = set.lower_bound(key)
|
set에서 지정된 키보다 크거나 같은 키를 가진 첫 번째 요소에 반복자를 반환.
|
|
set.max_size()
|
set의 최대 길이를 반환.
|
|
set.size()
|
집합에 있는 요소 수를 반환.
|
|
set.swap(set2)
|
두 set의 요소를 교환.
|
|
iter = set.upper_bound(key)
|
set에 지정된 키보다 큰 키를 가진 첫 번째 요소에 반복자를 반환.
|
|
pred = set.value_comp()
|
set에서 요소 값의 정렬에 사용되는 비교 개체의 복사본을 검색.
|
#include <iostream>
#include <set>
#include <cstdlib>
using namespace std;
int main() {
set<int, less<int>> s;
srand(time(NULL));
for(int i = 0; i < 10; i++){
auto ret = s.insert(rand() % 100);
if(!ret.second) {
cout << *ret.first << "가 이미 있습니다!" << endl;
}
}
set<int>::iterator it;
for(it = s.begin(); it != s.end(); it++){
cout << *it << " ";
}
cout << endl;
set<int, less<int>>:: key_compare kc = s.key_comp();
it = s.end();
it--;
if(kc(*s.begin(), *it)){
cout << "less" << endl;
}else {
cout <<"greater" << endl;
}
it = s.lower_bound(30);
auto ret2 = s.equal_range(*it);
cout << *(ret2.first) << ", " << *(ret2.second) << endl;
return 0;
}
결과값)
1 3 14 23 41 73 75 81 82 91
less
41, 73결과 값은 랜덤이기 때문에 실행할 때마다 다르게 나올거다. 체크하고 넘어갈 부분은 insert 시 pair 쌍으로 받으면 중복을 확인하는 쌍을 받을 수 있다. key compare의 경우 키들이 오름차순, 내림차순인지 판단할 수 있는 방법을 제공하고 equal range는 해당 값의 원소와 같거나 큰(first), 원소보다 큰(second) 쌍을 반환한다.
multiset 멀티셋
multiset은 이름 그대로 mutil 가 가능하다. 즉, set에서 중복을 허용하지 않았던 부분이 해소된 자료구조다.
C++, STL 연관 컨테이너(associative container), set, multiset : 네이버 블로그 (naver.com)
'CS > 자료구조 & 알고리즘' 카테고리의 다른 글
| 비헤이비어 트리 (Behavior Tree) (0) | 2023.08.17 |
|---|---|
| C++ 프림(Prim) 알고리즘으로 MST 찾기 (0) | 2023.08.12 |
| [C++] STL 연관 컨테이너(associative container), map, multimap (0) | 2023.08.11 |
| [C++] STL list(리스트), 시퀀스 컨테이너 (0) | 2023.08.11 |
| Union-Find (합집합 찾기) 알고리즘 (0) | 2022.12.19 |