
프로세서가 빈번하게 사용하는 데이터를 빠르게 추출하기 위한 '캐시 라인' 이라는 데이터 단위라고 불리며 데이터 저장구조로는 대표적으로 몇 가지 있다.
- Full Associative 방식
- Set Associative 방식
- Direct Map 방식
캐시 라인과 태그
프로세서는 다양한 주소에 있는 데이터를 사용하므로 일반적으로 빈번하게 사용하는 데이터의 주소는 여기저기 흩어져 있어서 캐시에 저장하는 데이터에는 해당 데이터의 메모리 주소 등을 쓴 태그를 달아놓을 필요가 있다. 그리고 메모리로부터 가져오는 데이터 묶음(단위)을 캐시 라인이라고 한다.

태그의 크기, 캐시 라인의 크기
캐시 라인에 붙이는 태그는 32비트 주소 공간을 갖는 프로세서는 32비트, 64비트 주소 공간을 갖는 프로세서는 64비트 정도의 크기가 필요하다. 그리고 캐시 라인을 너무 작게 잡으면 태그를 기억할 공간의 오버헤드가 커져 캐시 메모리의 총 비트 수 중에서 데이터 기록에 사용할 수 있는 부분이 작아진다. 반면, 캐시 라인의 크기를 크게 하면 메모리에서 큰 묶음으로 가져왔는데 그 중의 일부 데이터밖에 사용할 수 없고 대부분의 데이터는 쓸모 없게 되는 경우가 늘어난다.
양측의 밸런스를 고려해서 캐시 라인의 크기는 '32Byte~256Byte' 정도로 하는 것이 일반적이다. 이렇게 하면 64bit의 태그를 붙이더라도 태그를 기억하는데 필요한 메모리는 데이터의 1/4~1/32 정도로 과중한 부담은 되지 않는다.

메모리와 캐시 간 데이터 전송은 캐시 라인 단위
- 캐시는 메모리에서 가져온 데이터를 저장하는 '데이터 배열' 메모리에서 어느 주소에 위치한 데이터인지 등을 나타내는 '태그 배열' 데이터 배열에 읽고 쓰거나 태그 배열의 내용을 제어하는 '캐시 컨트롤러'로 구성되어 있다.
- 프로세서에서 특정 주소에 있는 데이터 로드 요청을 받았을 때 캐시 컨트롤러는 프로세서에서 받는 주소와 태그가 일치하는지를 체크한다.
- 태그가 일치하는 캐시 라인이 없는 경우는 요청받은 데이터는 캐시에 없으므로 해당 주소를 포함하는 캐시 라인 전체 데이터를 메모리에서 읽고 태그를 붙여서 비어 있는 캐시 라인에 저장한다.
- 캐시 라인 내의 요청받은 주소의 데이터를 프로세서에 보낸다.
프로세서가 특정 주소로 데이터 저장 요청을 한 경우는 처리과정이 좀더 복잡하다.

기억 해둬야할 점은 캐시는 프로세서의 로드나 스토어 명령이 요구하는 1~8Byte 데이터만을 메모리에서 가져오는 것이 아니라 캐시 라인 단위로 모아서 가져온다는 점이다. 그리고, 로드 명령의 경우는 메모리->캐시 로 1회만 읽으면 되지만 스토어 명령은 캐시->메모리, 캐시->메모리 로 메모리에 다시 쓸 필요가 있으므로 메모리 액세스가 2회 필요하는 점이다.
Full Associative 방식의 캐시 (자유도가 높다)
캐시는 각 캐시 라인을 보고 요청받은 데이터의 주소와 일치하면 해당 위치에 요청받은 데이터가 들어 있음을 알 수 있다. 이러한 태그 일치 체크는 끝에서부터 차례로 모든 캐시 라인을 조사해가게 되면 시간이 걸리므로 고속으로 데이터를 공급하려는 캐시 목적에 적합하지 않게 된다. 그래서 캐시 라인의 태그에 각각 비교회로를 장착해서 프로세서에서 요청하는 주소와 태그 간 일치 여부를 병렬로 체크하는 방식이다. 어느 캐시 라인에 어떤 데이터를 넣더라도 자유가 높다는 점에서는 좋은 방식이지만, 비교회로는 태그를 기억하는 메모리보다도 큰 칩 면적을 필요로 하고 또한 소비전력도 크므로 큰 용량의 캐시를 만들기에는 적합하지 않다. 따라서 통상의 데이터 캐시나 명령 캐시로는 사용하지 않는다.
Direct Map 방식의 캐시 (구조가 간단)
메모리 주소의 중간 비트값을 사용하는 캐시 라인을 선택해 엑세스할 주소에 따라 사용할 수 있는 캐시 라인이 정해진 방식이다.
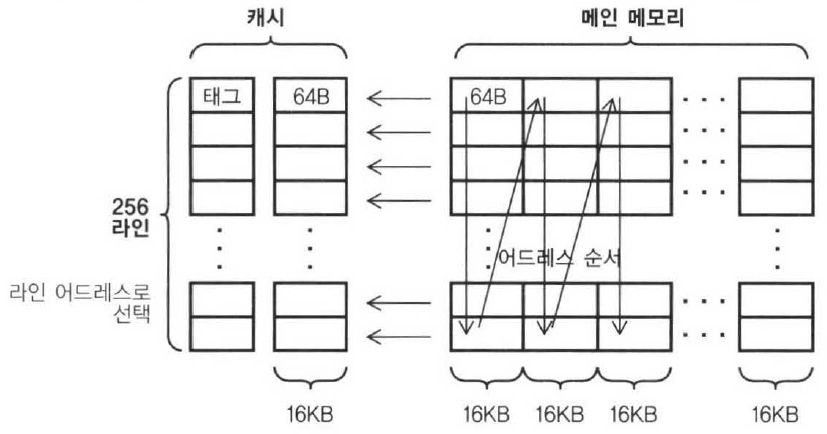
이 방식에서 캐시 라인의 수는 2가 된다. 이와 같이 하면 라인 주소마다 하나의 캐시 라인이 대응하므로 Direct Map 방식이라고 한다. Direct Map 방식은 메인 메모리를 캐시 용량 단위, 세로 방향 열로해서 해당 열이 가로로 나열되어 있고 각 열의 동일 높이 위치에 있는 64Byte 묶음은 가로방향의의 화살표에 쓰여진 캐시 라인에만 저장되도록 되어 있다. 다시 말하면, 높이가 같은 64Byte 묶음은 하나의 열 단위로 캐시 라인에 들어갈 수 있으며, 다른 열의 데이터가 들어갈 경우에는 이전에 들어 있는 데이터를 빼낼 필요가 있다는 것 이다.
이 구조에서는 메인 메모리의 주소를 구분한다. 최하위 6bit는 64Byte 캐시 라인 내의 바이트 위치를 나타내고 그 위에 8bit로 256개의 캐시 라인 중 하나를 선택한다. 그리고 남은 상위 주소 bit가 태그와 비교된다.
Direct Map 방식에는 프로세서가 요구하는 메모리 주소의 데이터를 가지고 있을 가능성이 있는 캐시 라인은 하나밖에 없으므로 해당 캐시 라인의 태그를 체크해서 일치하면 히트, 태그가 일치하지 않으면 미스 이다.
그리고나서 이 메모리에서 읽은 데이터를 저장할 캐시 라인은 라인 어드레스로 결정되는데, 결국 미스를 일으킨 캐시 라인에 저장할 필요가 있다. 이 캐시 라인이 갱신되지 않은 경우는 그대로 덮어써버려도 되지만, 스토어 명령으로 갱신되는 경우는 먼저 데이터 배열의 내용을 태그 주소를 이용해서 메모리에 쓸 필요가 있다.
Thrashing ( 캐시 라인 쟁탈에 의한 성능저하 )
Direct Map 방식은 주소 비교회로가 1개면 하드웨어로는 간단하지만, 동일한 캐시 라인에 대응하는 서로 다른 메모리 주소 데이터를 서로 번갈아 가며 액세스하면 문제가 발생한다.
double a[2048], b[2048];
for( i = 0; i < N; i++ ) a[i] = b[i];
위와 같은 프로그램에서 배열 a,b의 각각은 8Byte 2048개 요소의 배열이므로 크기는 16KB가 된다. 따라서 16KB 인 Direct Map 방식의 캐시의 경우는 a[i]와 b[i]가 같은 캐시 라인에 대응하게 된다.
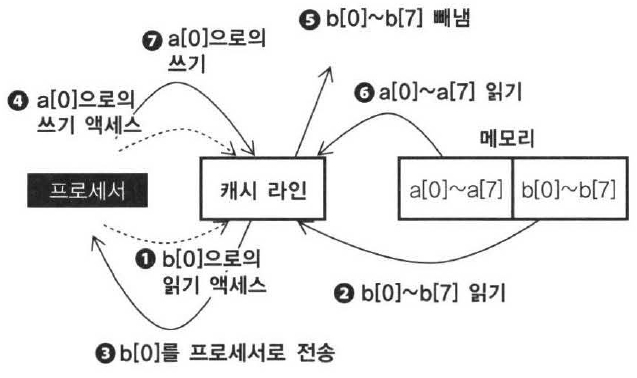
그렇게 되면 프로세서는 먼저 ①에서 b[0]을 읽으므로 ②에서 b[0]을 포함하는 데이터를 메모리로부터 읽어서 캐시에 넣고, ③에서 프로세서에 b[0]데이터를 보내고 프로세서는 b[0]을 레지스터에 저장한다. 다음에 ④에서 프로세서는 해당 데이터를 a[0]에 저장하는 스토어 명령을 실행한다. 그러나 해당 캐시 라인에는 b[0]~b[7]이 들어 있으므로 태그는 일치하지 않는다. 따라서 캐시는 a[0]을 포함하는 데이터를 메모리로부터 읽어내서 캐시에 넣으려고 하지만, b[0]을 넣었던 것과 동일한 캐시 라인이므로 ⑤와 같이 b[0]은 캐시로부터 빼내진다. 그리고 ⑥에서 메모리로부터 a[0]을 캐시 라인으로 읽고 ⑦에서 a[0]에 데이터를 저장한다.
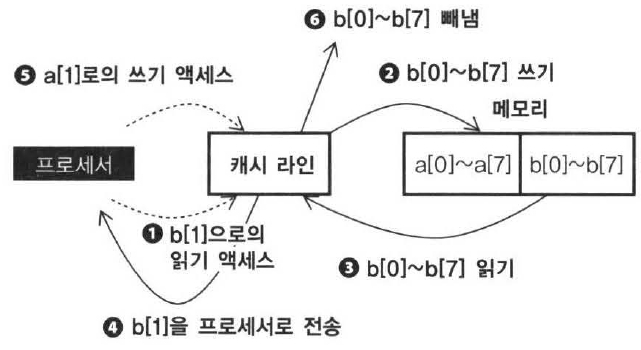
그리고나서 다음 번 루프에서는 ①에서 프로세서는 b[1]의 로드 명령을 실행한다. b[1]은 b[0]과 같은 캐시 라인에 포함되어 있지만, 안타깝게도 해당 캐시 라인은 a[0]을 포함하는 캐시 라인을 넣기 위해 빼내지는 것이므로 태그는 일치하지 않는다. 그래서 이번에는 a[0]의 캐시 라인을 빼내서 캐시를 비울 필요가 있다. 그러나 a[0]은 갱신되고 있으므로 ②처럼 캐시 라인 전체를 메모리에 되돌려 쓸 필요가 있다. 이후 동일한 캐시 라인에 b[i+1]을 넣기 위해 a[i]를 빼내고 a[i+1]을 넣기 위해 b[i+1]을 빼내는 동작이 계속 된다. 이와 같이 양쪽 데이터가 동일한 캐시 라인을 쟁탈하기 위해 빈번하게 캐시 교체가 일어나는 상황을 Thrasing 이라고 한다. 이렇게 되면 캐시는 오히려 역효과를 내면서 극적으로 성능이 저하되게 된다.
Thrasing에 대한 대처 예
double a[2048], dummy[8], b[2048];과 같이 배열 a와 b정의 사이에 캐시 라인 크기의 dummy 배열을 넣으면, b[i] 에서 사용하는 캐시 라인 번호는 a[i]에서 사용하는 캐시 라인 번호보다 1이 더 커서 서로 다른 캐시 라인을 사용하게 된다.
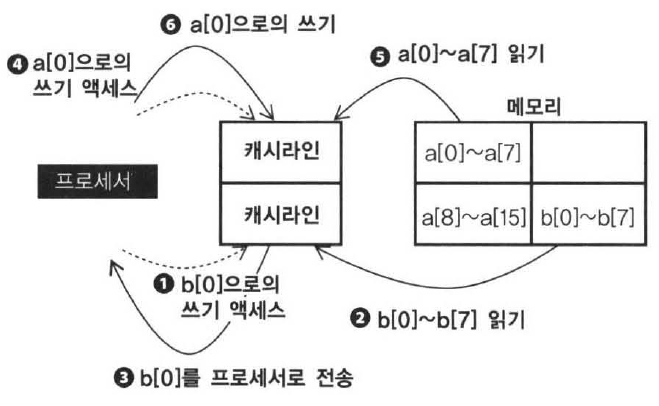
①부터 ⑤까지 루프를 한 번에 끝낸 시점에서 최초 캐시 라인에는 a[0]~a[7], 두 번째 캐시 라인에는 b[0]~b[7]이 저장되어 있으므로 2회째부터 7회째 루프까지는 메모리 액세스 할 필요가 없고 캐시 본래의 동작이 되어 Thashing이 발생하지 않게 할 수 있다. 만일을 위해 보충 설명을 하면, 캐시는 소프트웨어에서 보이지 않은 존재이므로 Thrashing에 관해서는 컴파일러에서 최적화 할 수 없다.
Set Associative 방식 ( 좋은 점을 취한 중간적인 방식 )
Direct Map 방식의 캐시는 메모리 주소에 대응하는 캐시 라인이 직접 정해져 있어서 캐시 라인의 경합이 발생하기 쉽다는 결점이 있다. 이를 해결하는 수단으로 등장한 것이 Set Associative 방식이다. Set Associative 방식은 각각의 메모리 주소에 대응하는 캐시 라인을 여러개 갖추도록 한다. 이 캐시 라인의 그룹을 '세트(set)' 라고 한다. 세트에 포함되는 캐시 라인은 2개이므로 이 구성은 '2way Set Associative'라고 한다.
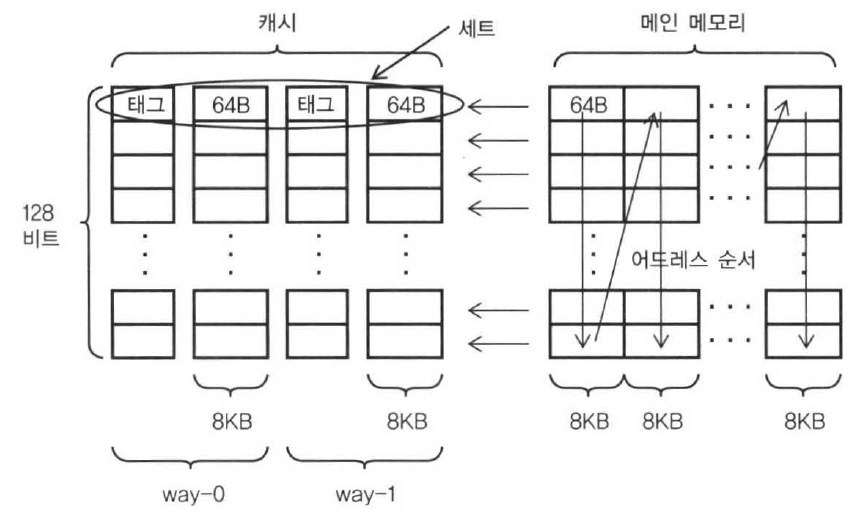
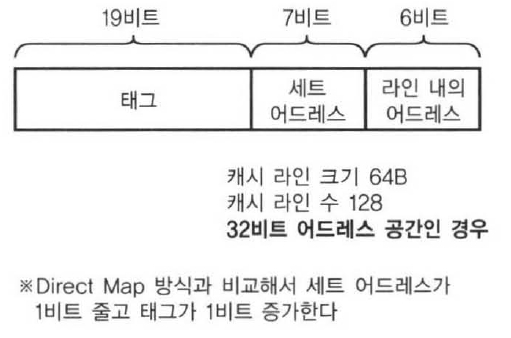
캐시의 용량을 Direct Map의 예와 동일하게 16KB로 하면, 세트의 수는 절반인 128세트가 된다. 이 때문에 세트 선택에 사용하는 주소 비트는 7bit가 되고 태그가 1bit 증가한다.
캐시는 액세스된 메모리 주소 내의 세트 주소의 부분을 사용해서 세트를 선택하고, 메모리 주소의 태그 부분과 세트가 포함되는 모든 캐시 라인의 태그와 비교를 병렬로 수행한다. 이와 같이 세트 내에서는 Full Associative 방식과 마찬가지로 병렬로 일치 여부를 찾으므로, 이 방식은 'Set Associative' 라고 이름 붙혀졌다. 예에서는 2way 밖에 없으므로 선택된 세트인 way-0과 way-1의 태그와의 일치를 동시에 비교해서 어느 한쪽에 일치하면 히트가 되고, 모두 일치하지 않으면 미스가 된다. 미스가 돼서 메모리로부터 데이터를 읽어오게 될 경우 Direct Map 방식의 경우는 넣을 수 있는 캐시 라인이 하나밖에 없지만, Set Associative 방식은 세트 내의 어떤 캐시 라인을 빼내서 비우더라도 상관없게 된다.
LRU ( 내보낼 라인의 선택 )
내보낼 라인 선택은 랜덤으로 적당히 선택하거나 혹은 캐시에 들어간 시점이 오래된 것부터 차례로 내보내는 FIFO라는 방식도 있지만, 널리 사용되고 있는 것은 LRU(Least Recently Used) 라는 방식이다. LRU는 각 세트에 대해 각각의 Way가 사용된 순서를 기억해두고 마지막으로 사용된 시점이 가장 오래된 Way를 내보낸다.
Set Associative 방식의 특징
앞서 말했듯이 세트에는 복수의 캐시 라인이 포함되어 있어 메모리로부터의 데이터는 세트 내의 어떤 캐시 라인에도 저장할 수가 있다. 즉, Set Associative 방식은 각각의 주소의 데이터를 저장할 수 있는 캐시 라인이 여러 개 있다고 하는 자유도를 가지는 반면, 메모리 주소의 일부를 사용해서 세트를 선택함으로써 태그의 비교회로수를 적은 수로 억제하는 Full Associative 방식과 Direct Map 방식의 좋은 점을 함께 갖춘 중간적인 방식이다. 앞에서 작성한 a[i] = b[i]의 루프와 같은 경우에는 2Way Set Associative 캐시로 하면 b[i]는 way-0, a[i]는 way-1을 사용하므로 dummy 배열을 넣지 않더라도 Thrashing은 해결된다. 그러나 Set Associative 방식에서도 사용하는 배열 수가 늘어나면 Thrashing이 발생할 가능성이 있어 완전하게 회피할 수 있는 것은 아니다. 캐시에서는 어느 정도 시간범위 내에서 동시에 사용하는 데이터에 할당된 캐시 라인의 경합이 발생하지 않는 것이 좋으므로 Full Associative 방식 정도로 자유도를 끌어올릴 필요는 없다. 오늘날에는 모든 상용 마이크로프로세서의 데이터 캐시나 명령 캐시는 Set Associative 방식을 사용하고 있다고 해도 과언은 아니다.
캐시를 잘 사용하는 프로그래밍
캐시는 메모리로부터 데이터를 64Byte 등의 묶음으로 가져오므로 가져온 데이터의 일부만 사용하면 나머지 데이터는 낭비가 된다. 따라서 시간적으로 근접한 일련의 처리에서는 사용되는 데이터는 가능한 적은 수의 캐시 라인에 밀어 넣는 편이 캐시 히트율을 높이게 된다. 일반적인 프로그램 언어에서는 변수의 정의를 쓰면 변수영역의 선두는 캐시 라인 크기의 정수배인 주소가 되고, 거기서부터 정의한 순으로 각 변수에 주소가 할당된다. 따라서 처리단위별로 사용빈도가 높은 변수를 모아서 정의하면 변수들은 동일한 캐시 라인에 들어가서 캐시 히트율을 개선할 수 있는 가능성이 높아진다. 이와 같은 프로그래밍은 사람의 사고와도 일치하고 자연스런 감각이라고 생각하지만, 프로그램을 작성하면 캐시 라인의 유효이용 관점에서 변수정의 순서를 재점검하여 캐시의 히트율을 개선할 수도 있을 것이다.
'CS > OS & 하드웨어' 카테고리의 다른 글
| 프로세서, 메모리, 캐시 개념 및 원리 (메모리 및 버스/연결 관한) (0) | 2022.10.18 |
|---|---|
| CPU의 역사 (0) | 2022.08.26 |
| CPU 프로세서 CISC / RISC 차이 (0) | 2022.08.10 |
| CPU 그리고 캐시 메모리 (0) | 2022.08.10 |
| CPU 32비트 64비트와 두 프로그램의 차이 (0) | 2022.07.31 |